Logistic Regression 💻
MATH 4780 / MSSC 5780 Regression Analysis
Regression vs. Classification
- Linear regression assumes that the response \(Y\) is numerical.
- In many situations, \(Y\) is categorical.
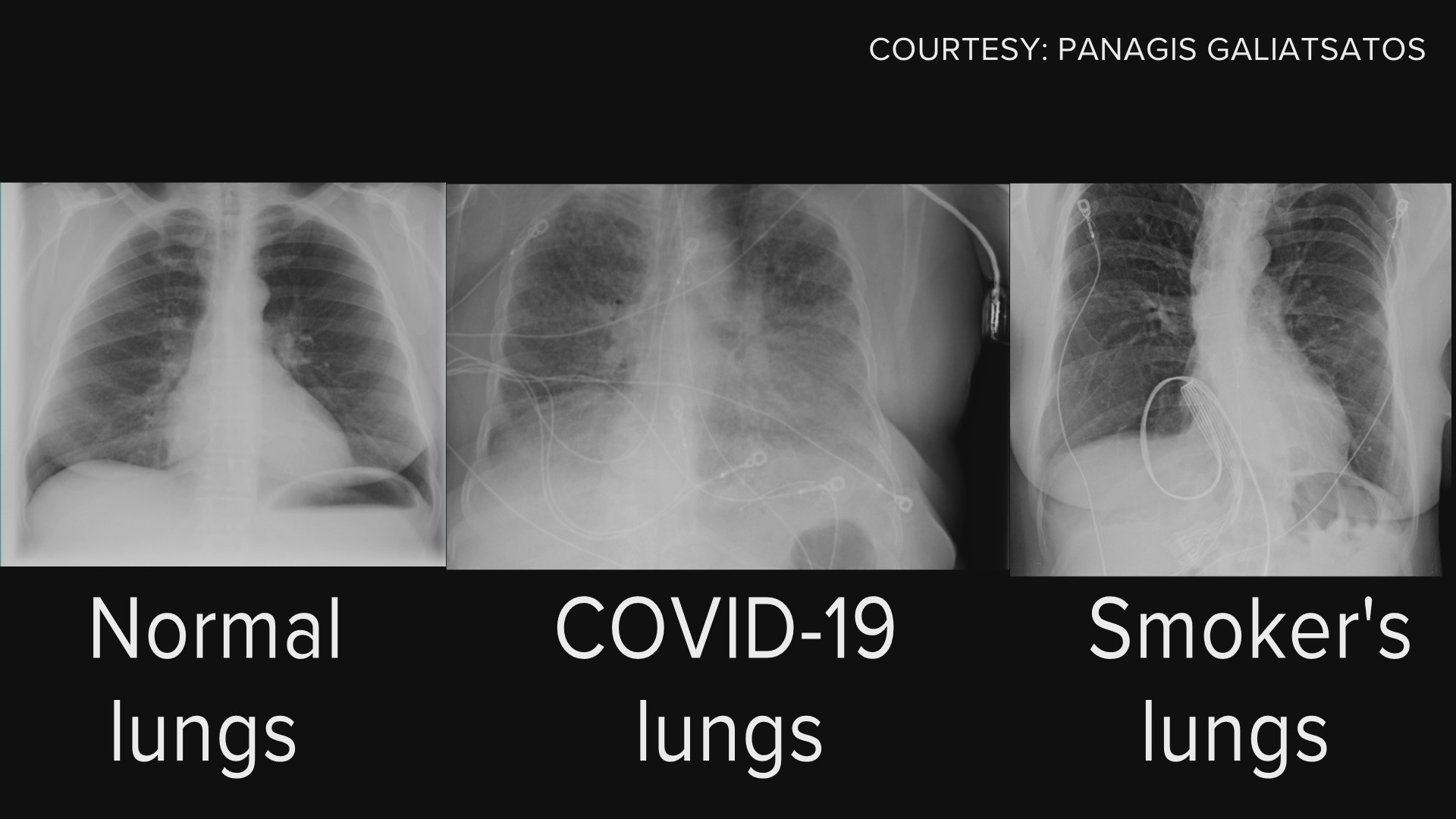
Normal vs. COVID vs. Smoking
fake news vs. true news

- A process of predicting categorical response is known as classification.
Regression Function \(f(x)\) vs. Classifier \(C(x)\)

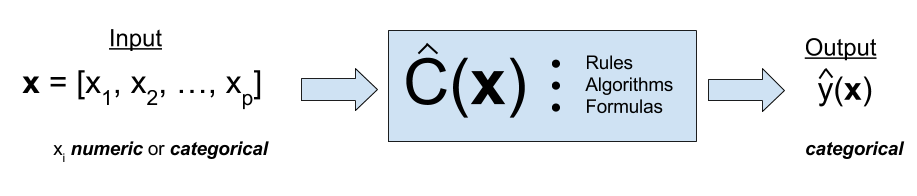
Classification Example
- Predict whether people will default on their credit card payment \((Y)\)
yesorno, based on monthly credit card balance \((X)\). - We use the (training) sample data \(\{(x_1, y_1), \dots, (x_n, y_n)\}\) to build a classifier.


Why Not Linear Regression?
- Some estimates are outside \([0, 1]\).
Why Not Linear Regression?
- First predict the probability of each category of \(Y\).
- Predict probability of
defaultusing a S-shaped curve.
Binary Responses with Nonconstant Probability
- Two outcomes: default \((y = 1)\) and not default \((y = 0)\)
- The probability of success \(\pi\) changes with the value of predictor \(X\)!
- With a different value of \(x_i\), each Bernoulli trial outcome \(y_i\) has a different probability of success \(\pi_i\):

\(y_i \mid x_i \stackrel{indep}{\sim} Bernoulli(\pi(x_i)) = binomial(m=1,\pi = \pi(x_i))\)
-
\(X =\)
balance. \(x_1 = 2000\) has a larger \(\pi_1 = \pi(2000)\) than \(\pi_2 = \pi(500)\) with \(x_2 = 500\) because credit cards with a higher balance tend to be default.
Logit function \(\eta = logit(\pi) = \ln\left(\frac{\pi}{1-\pi}\right)\)
Logistic Function \(\pi = logistic(\eta) = \frac{\exp(\eta)}{1+\exp(\eta)}\)
\(\eta\) vs. \(x\)
- \(\hat{\eta} = \text{logit}(\hat{\pi}) = \ln \left( \frac{\hat{\pi}}{1 - \hat{\pi}}\right) = -10.651 + 0.0055 \times \text{balance}\)
Probability Curve
- The relationship between \(\pi(x)\) and \(x\) is not linear! \[\pi(x) = \frac{\exp(\beta_0+\beta_1 x)}{1+\exp(\beta_0+\beta_1 x)}\]
- The amount that \(\pi(x)\) changes due to a one-unit change in \(x\) depends on the current value of \(x\).
- Regardless of the value of \(x\), if \(\beta_1 > 0\), increasing \(x\) will be increasing \(\pi(x)\).
Probability Curve
What is the probability of default when the balance is 500? What about balance 2500?
- 500 balance: Pr(default) = 0
- 2000 balance, Pr(default) = 0.59
- 2500 balance, Pr(default) = 0.96
R Lab Receiver Operating Characteristic (ROC) Curve
- Receiver operating characteristic (ROC) curve plots True Positive Rate (Sensitivity) vs. False Positive Rate (1 - Specificity)
- Packages: ROCR, pROC, yardstick::roc_curve()
library(ROCR)
# create an object of class prediction
pred <- ROCR::prediction(
predictions = pred_prob,
labels = Default$default)
# calculates the ROC curve
roc <- ROCR::performance(
prediction.obj = pred,
measure = "tpr",
x.measure = "fpr")plot(roc, colorize = TRUE)
R Lab Area Under Curve (AUC)
Find the area under the curve:
## object of class 'performance'
auc <- ROCR::performance(
prediction.obj = pred,
measure = "auc")
auc@y.values[[1]]
[1] 0.948
R Lab ROC Curve Comparison
Which model performs better?
Remember! Compare the candidates using the test data.
![]()