Categorical Variables 🛠
MATH 4780 / MSSC 5780 Regression Analysis
Categorical Variable in Regression
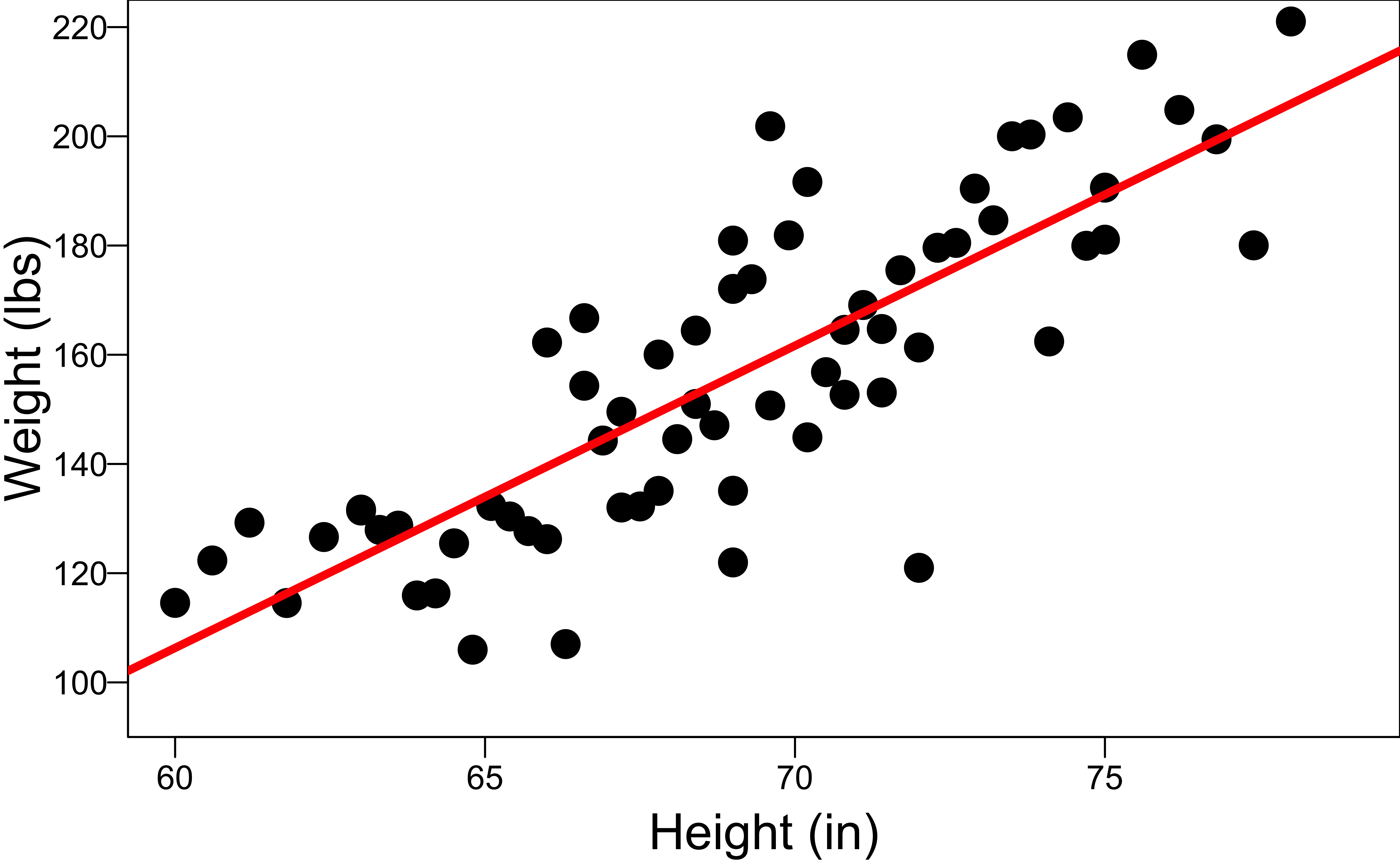
With categorical variable Gender

- Inappropriate height-weight relationship if gender factor is ignored.
- The two groups have different \(\beta_0\) and \(\beta_1\).
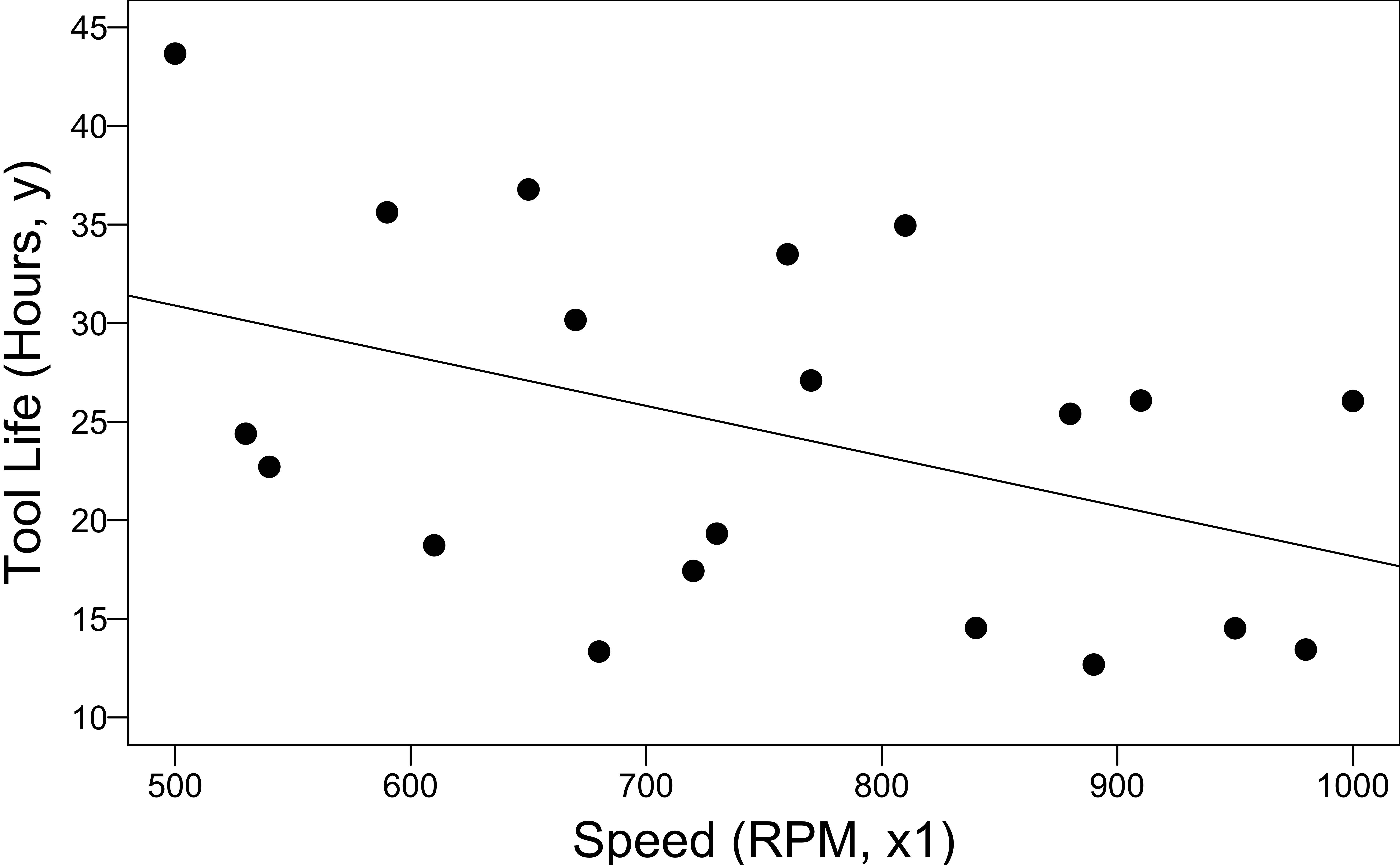
Example 8.1 Tool Life Data (LRA)
Relate the effective life (hours) of a cutting tool \((y)\) used on a lathe to
the lathe speed in revolutions per minute \((x_1)\) (Numerical)
the type of cutting tool used \((x_2)\) (Categorical)
Indicator Variable
- Tool type can be represented as: \[x_2 = \begin{cases} 0 & \quad \text{Tool type A}\\ 1 & \quad \text{Tool type B} \end{cases}\] where \(x_2\) is a dummy variable.
- If a first-order model is appropriate: \[y = \beta_0+\beta_1x_1+\beta_2x_2 + \epsilon, \quad \epsilon \sim N(0, \sigma^2)\]
- Assume that the variance is the same for both levels (type A and B).

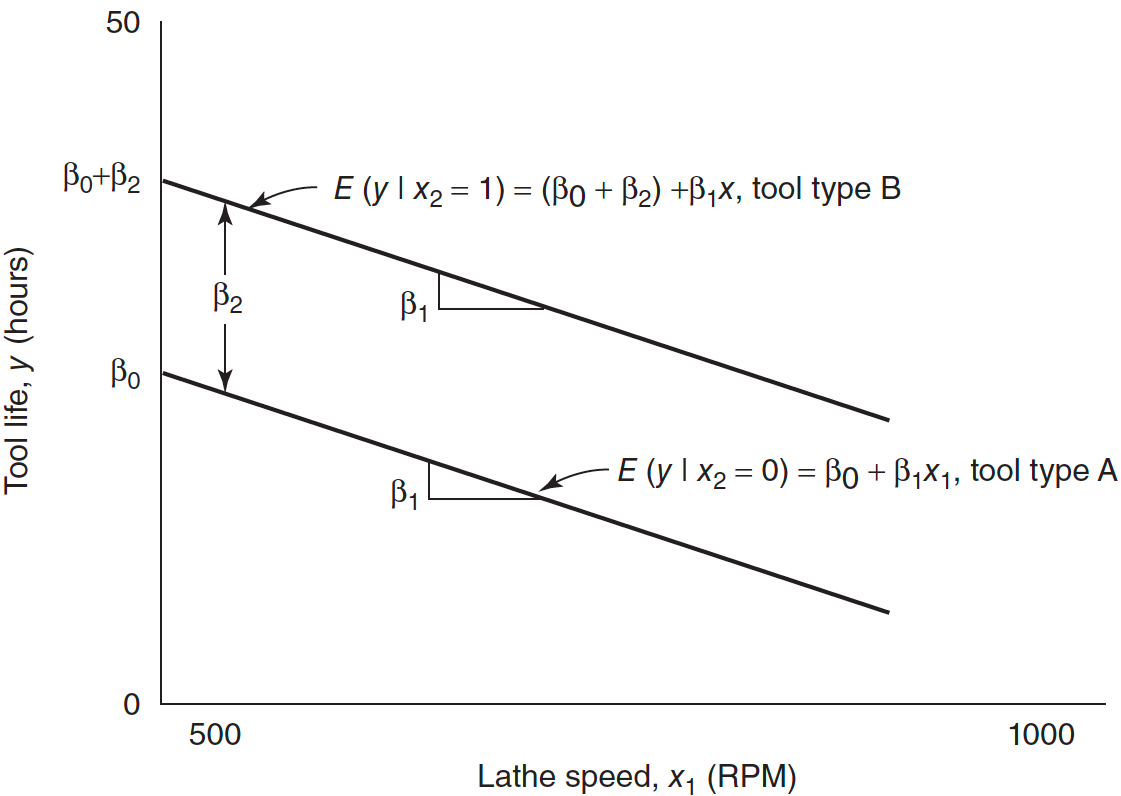
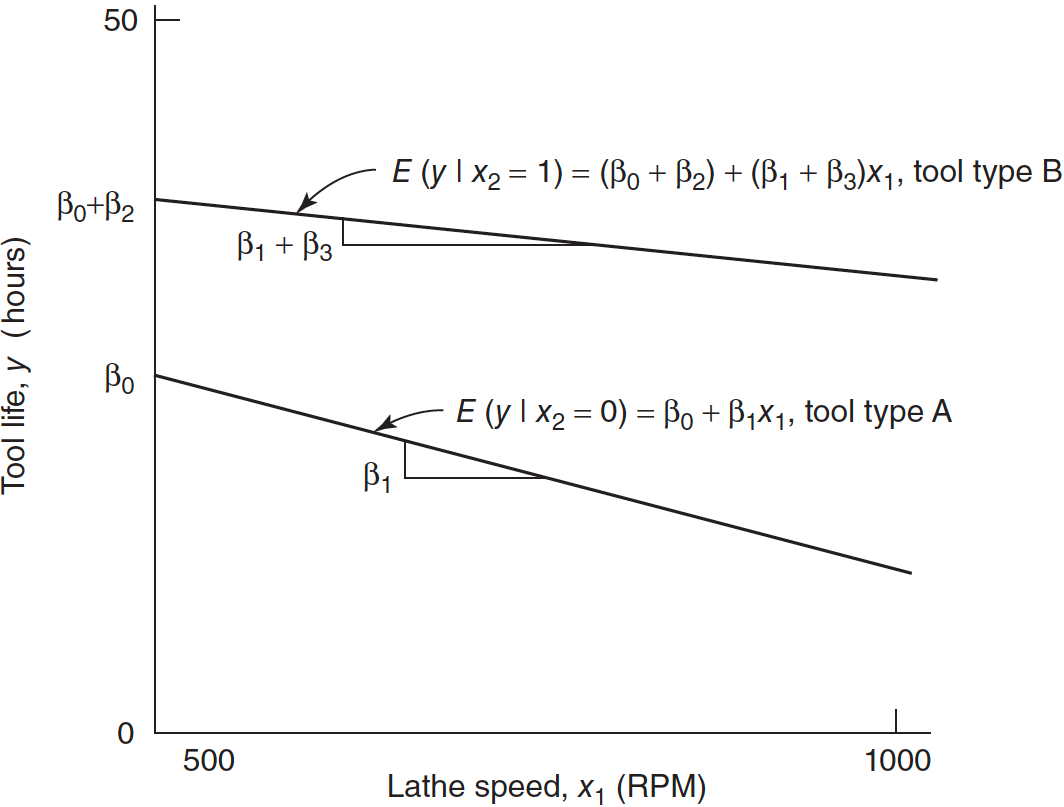
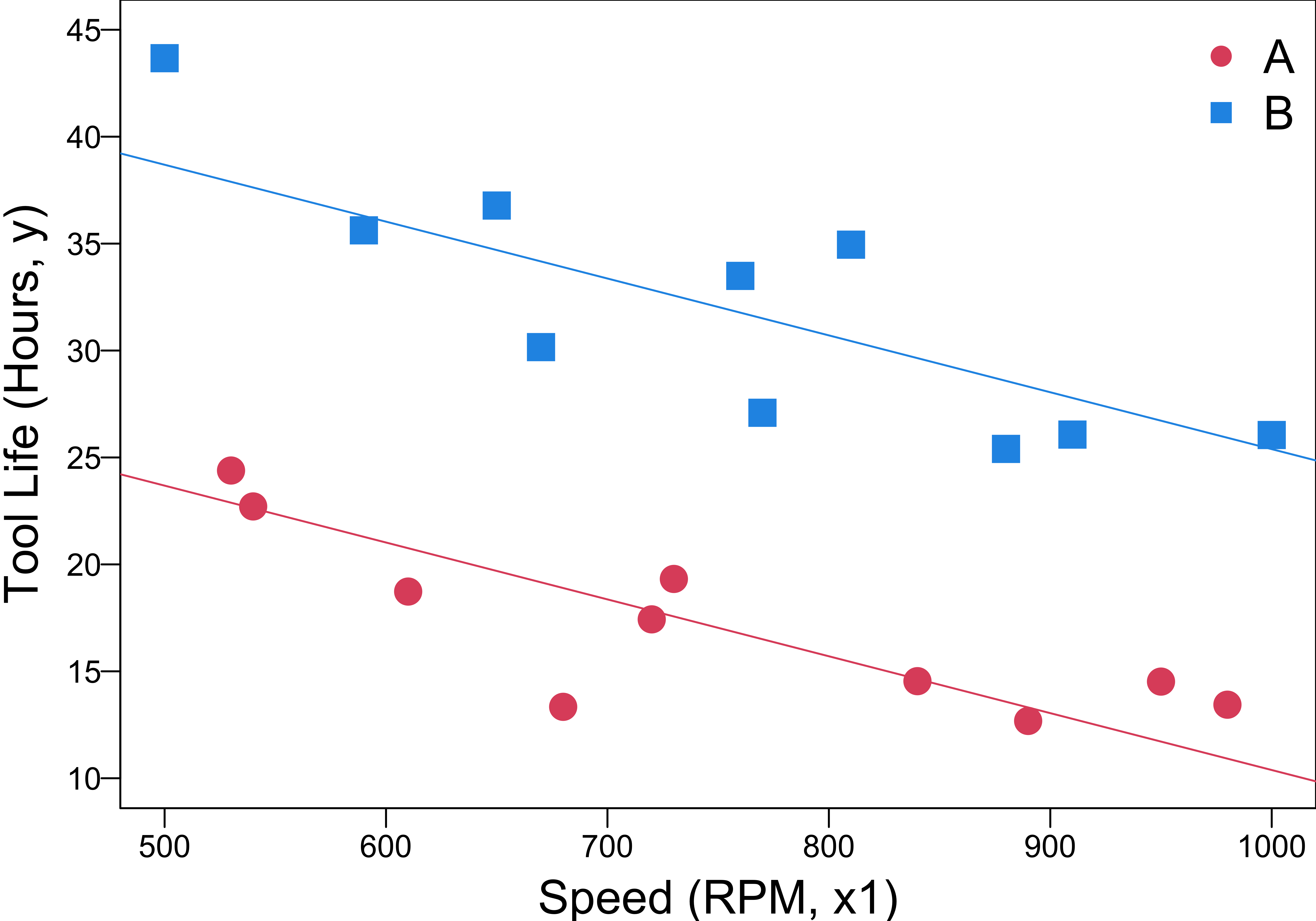
Parallel Regression Lines
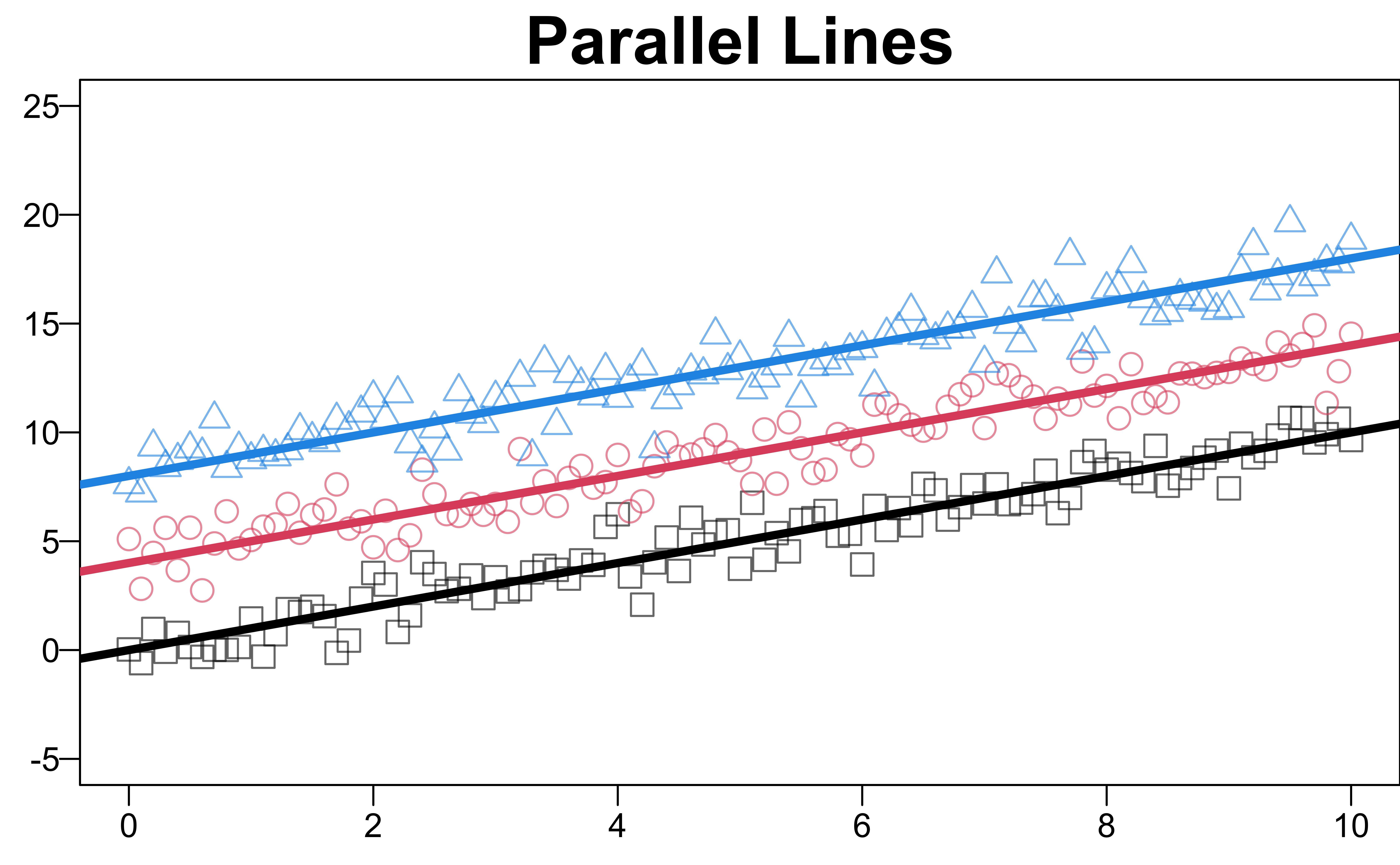
- Two parallel regression lines with a common slope \(\beta_1\) and different intercepts.
- \(\beta_2\) measures the difference in mean tool life resulting from changing from tool type A to B.
\(y = \beta_0+\beta_1x_1+\beta_2x_2 + \epsilon\)
\(\hat{y} = b_0 + b_1 x_1 + b_2 x_2\)
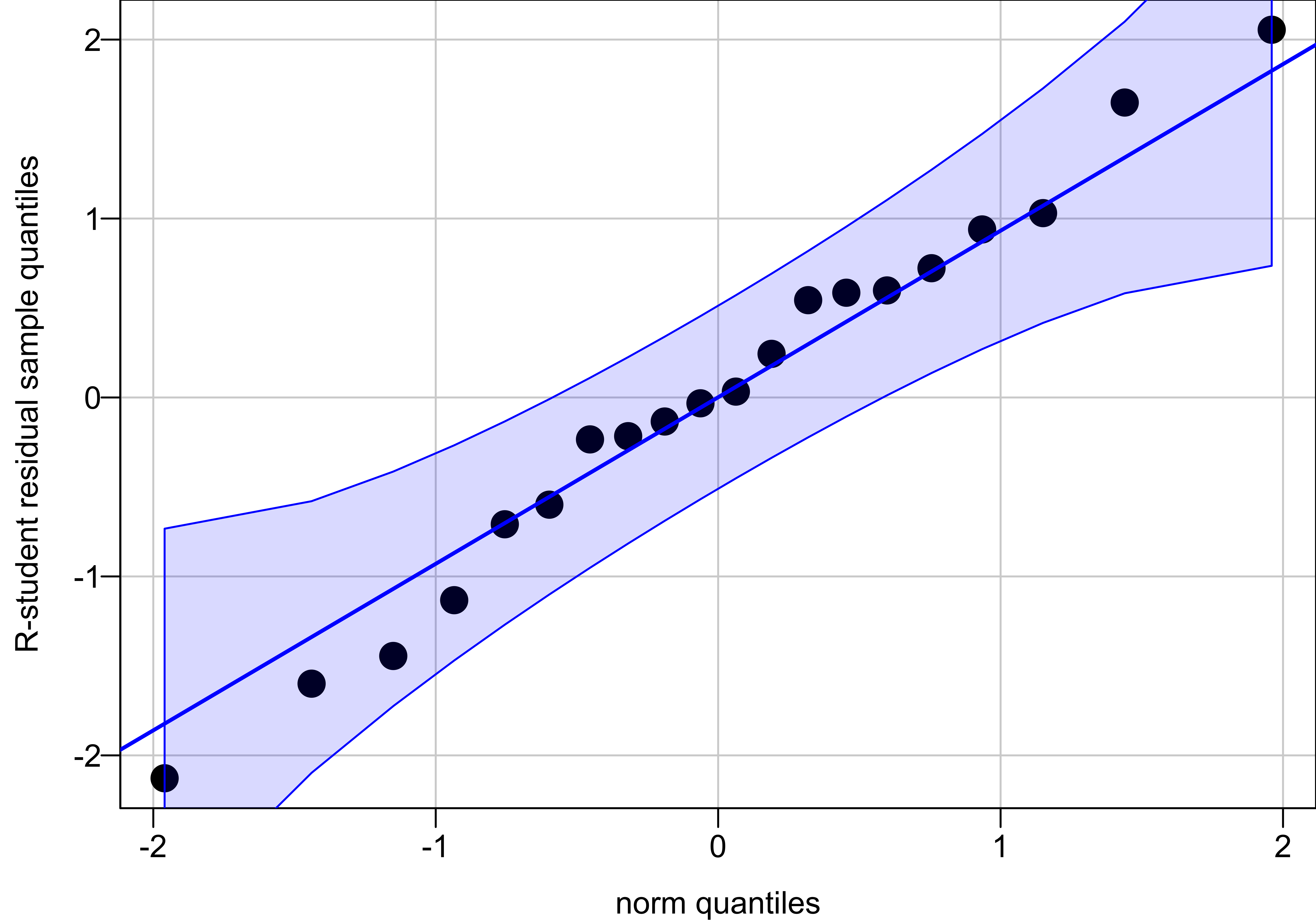
Model Checking
Same variance of the errors for both A and B?
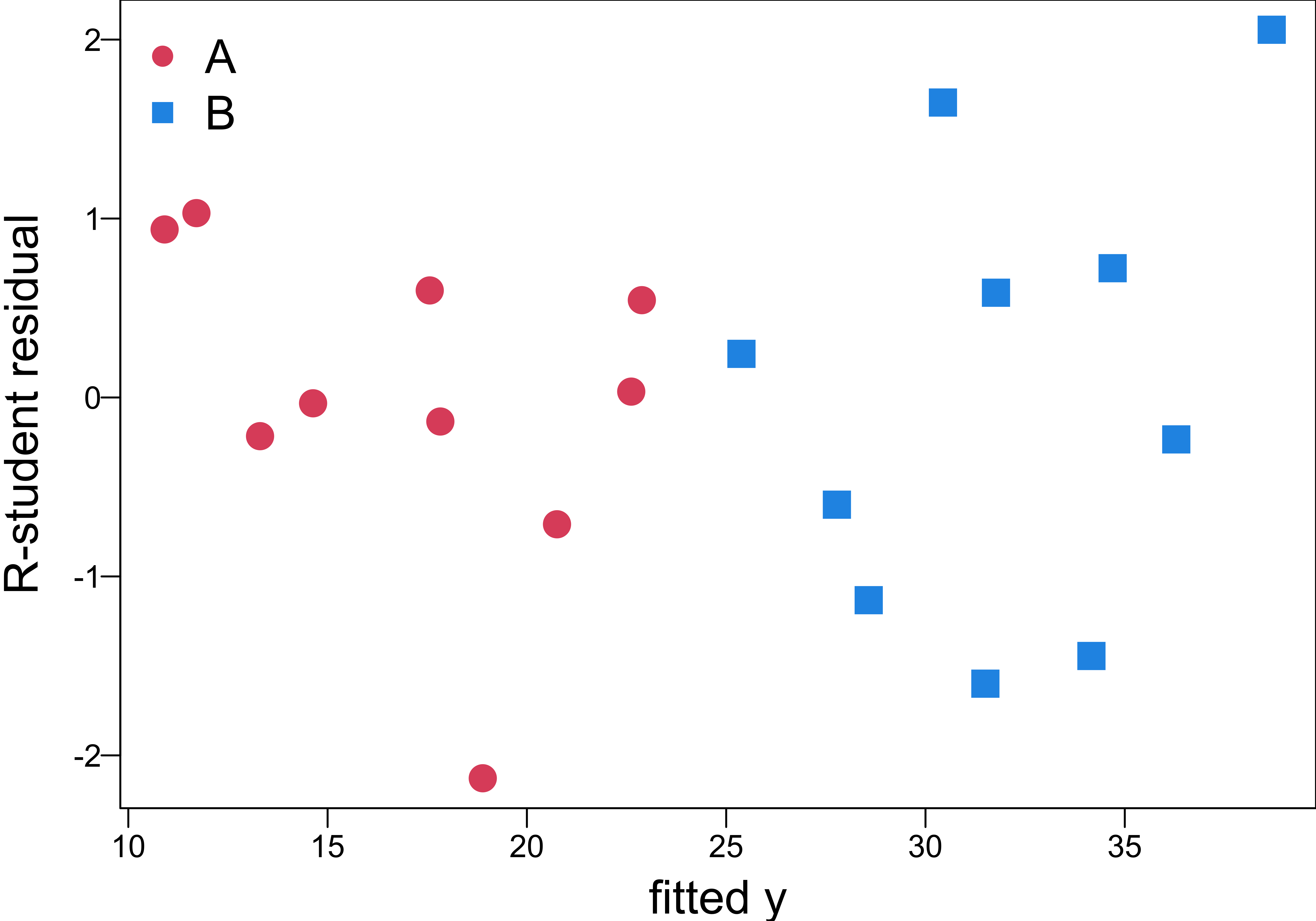
Approximately normal
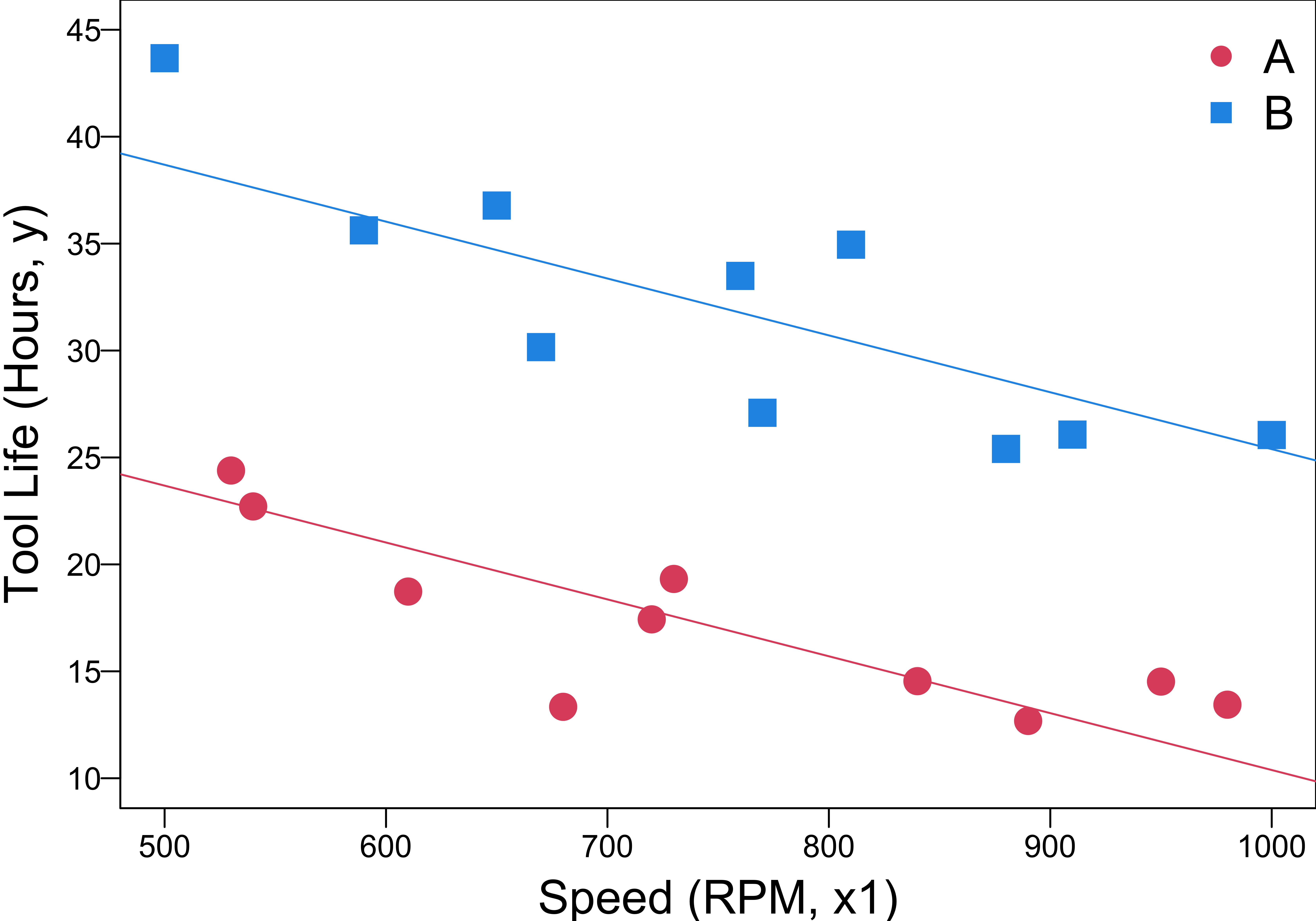
Response Function for the Tool Life Example
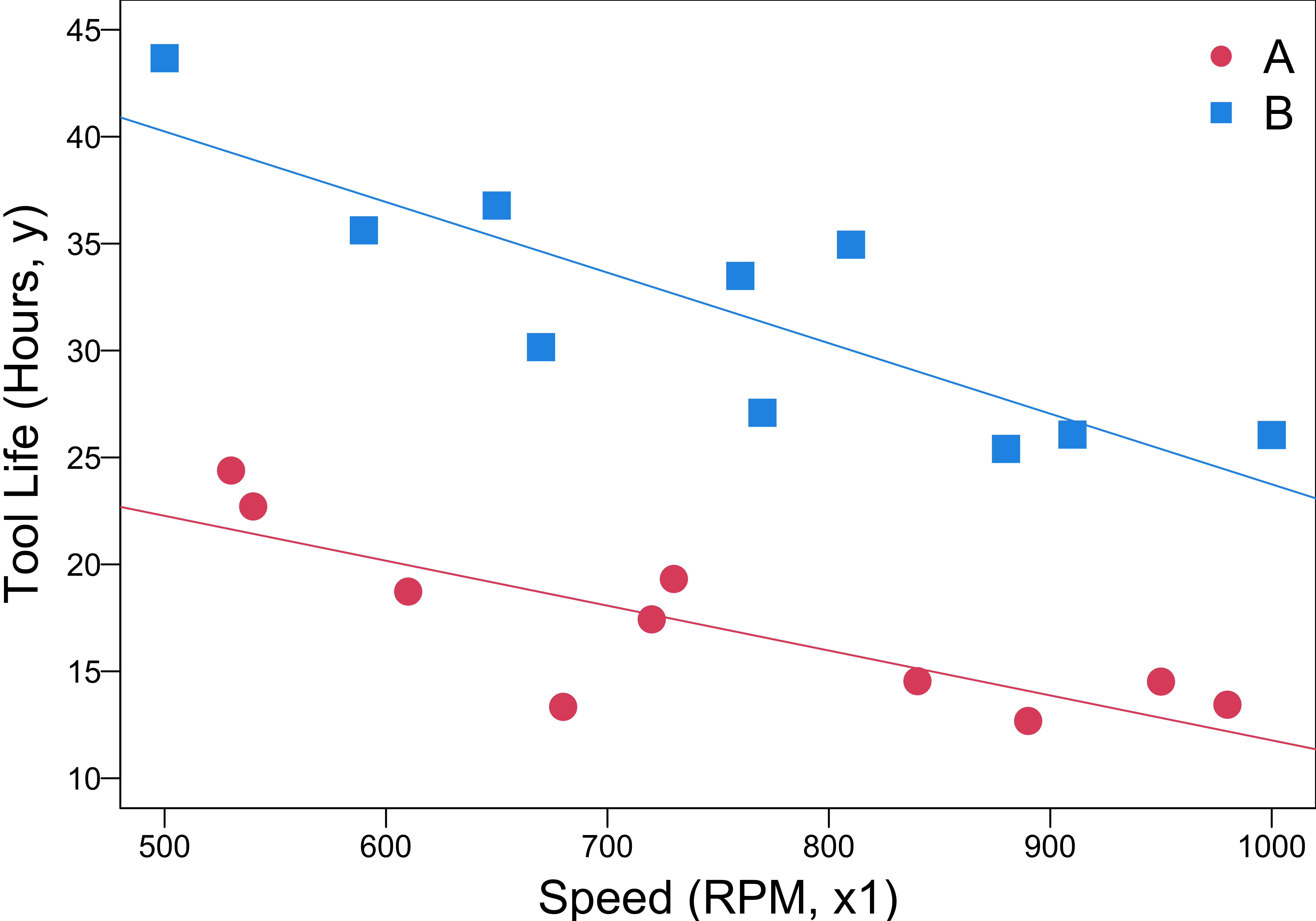
- \(y = \beta_0+\beta_1x_1+\beta_2x_2 + \beta_3x_1x_2 + \epsilon\) defines two regression lines with different slopes and intercepts.
\(y = \beta_0+\beta_1x_1+\beta_2x_2 + \beta_3x_1x_2+\epsilon\)
\(\hat{y} = b_0 + b_1 x_1 + b_2x_2 + b_3 x_1 x_2\)
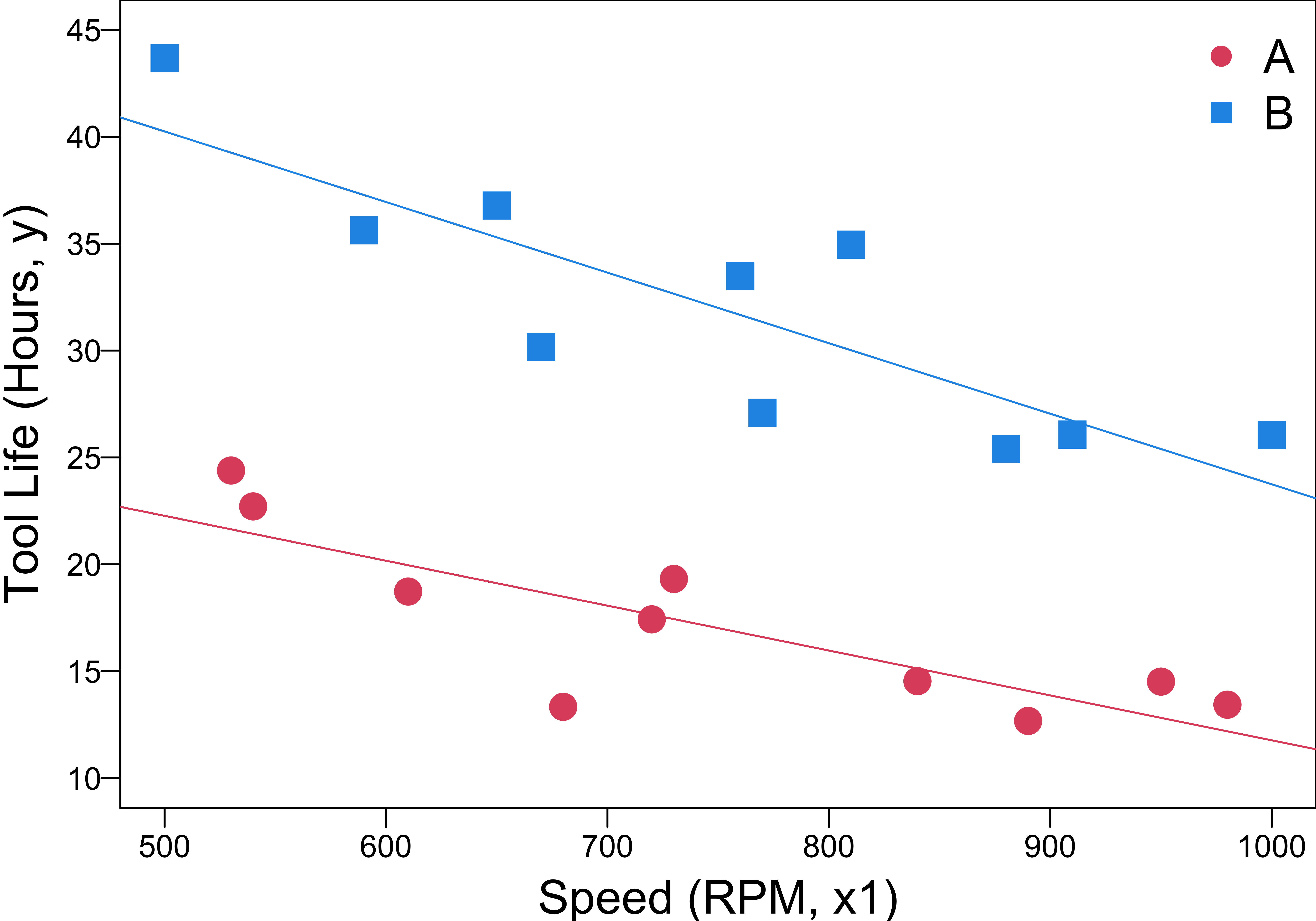
R Lab Regression Lines
\(y = \beta_0+\beta_1x_1+\beta_2x_2 + \epsilon\)
\(y = \beta_0+\beta_1x_1+\beta_2x_2 + \beta_3x_1x_2+\epsilon\)
Comparing Regression Models
- Consider simple linear regression where the \(n\) observations can be formed into \(M\) groups, with the \(m\)-th group having \(n_m\) observations.
- The most general model consists of \(M\) separate equations: \[y = \beta_{0m} + \beta_{1m}x + \epsilon, \quad m = 1, 2, \dots, M\]
- We are interested in comparing this general model to a more restrictive one.
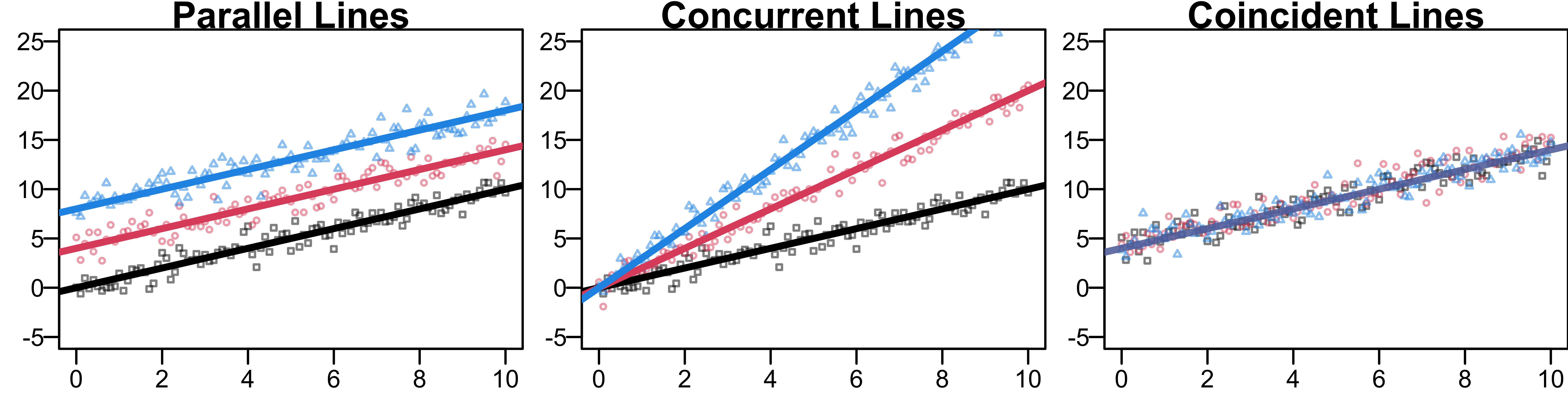
Parallel Lines (Example 8.1 where \(M = 2\))
All \(M\) slopes are identical \(H_0: \beta_{11} = \beta_{12} = \cdots = \beta_{1M} = \beta_1\)
Full Model \((F)\): \(y = \beta_{0m} + \beta_{1m}x + \epsilon, \quad m = 1, 2, \dots, M\).
Reduced Model \((R)\): \(y = \beta_0 + \beta_1x + \color{blue}{\beta_2D_1 + \beta_3D_2 + \cdots + \beta_{M-1}D_{M-1}}+\epsilon\), where \(D_1, \dots, D_{M-1}\) are dummies.
-
\(F_{test} = \frac{(SS_{res}(R) - SS_{res}(F))/(df_{R} - df_{F})}{SS_{res}(F)/df_{F}}\)
- \(df_{R} = n - (M+1)\)
- \(df_{F} = n - 2M\)
- \(SS_{res}(F)\) is the sum of \(SS_{res}\) from each separate regression
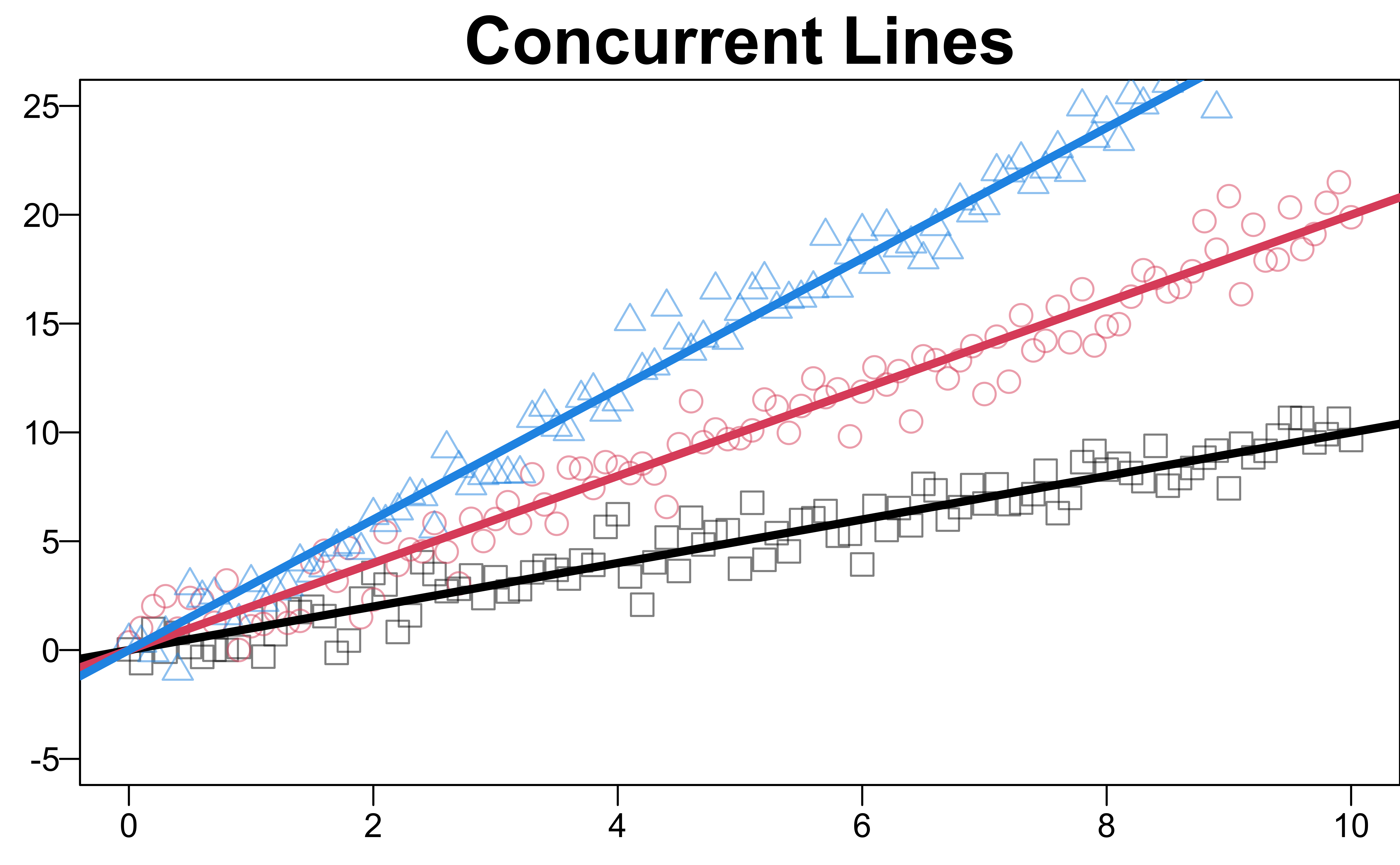
Concurrent Lines
- All \(M\) intercepts are equal, \(H_0: \beta_{01} = \beta_{02} = \cdots = \beta_{0M}= \beta_0\)
-
Reduced model: \(y = \beta_0 + \beta_1x + \color{blue}{\beta_2xD_1 + \beta_3xD_2 + \cdots + \beta_{M-1}xD_{M-1}}+\epsilon\).
- \(df_{R} = n - (M+1)\)
- Assume concurrence at the origin.
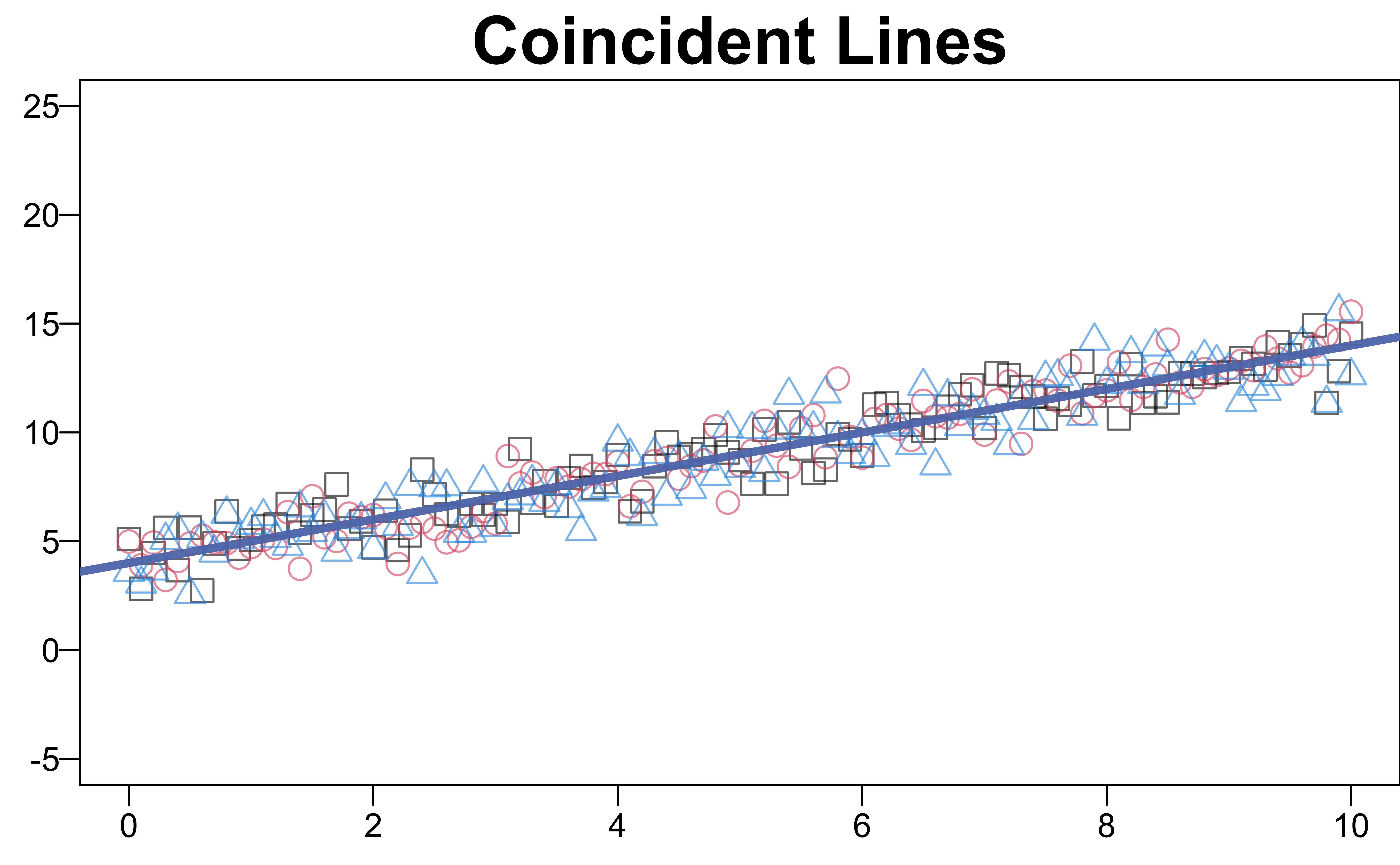
Coincident Lines
- Both the \(M\) slopes and the \(M\) intercepts are the same,
\(H_0: \beta_{11} = \beta_{12} = \cdots = \beta_{1M} = \beta_1\), \(\beta_{01} = \beta_{02} = \cdots = \beta_{0M} = \beta_0\) -
Reduced model: \(y = \beta_0 + \beta_1x+\epsilon\)
- \(df_{R} = n - 2\)
- Dummy variables are not necessary in the test of coincidence.
![]()