Simulation-based Inference 💻
MATH 4780 / MSSC 5780 Regression Analysis
Rent in Manhattan
How much do you think it costs to rent a typical 1 bedroom apartment in Manhattan?
Parameter of Interest
- Could focus on the median rent or mean rent depending on our research goal.
Observed Sample vs. Bootstrap Population
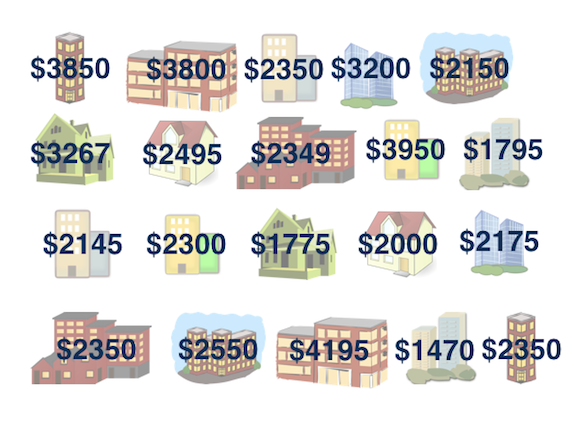
Sample median = $2350 😱
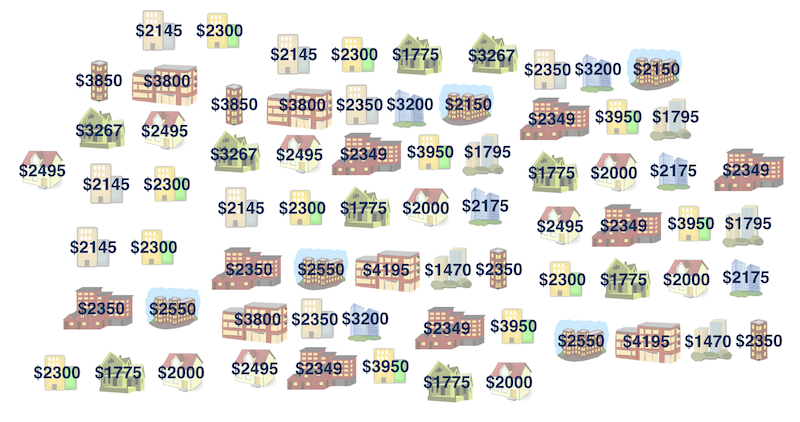
Population median = ❓
IDEA: We think the sample is representative of the population, so create an artificial population by replicating the subjects from the observed ones.
Bootstrap Population
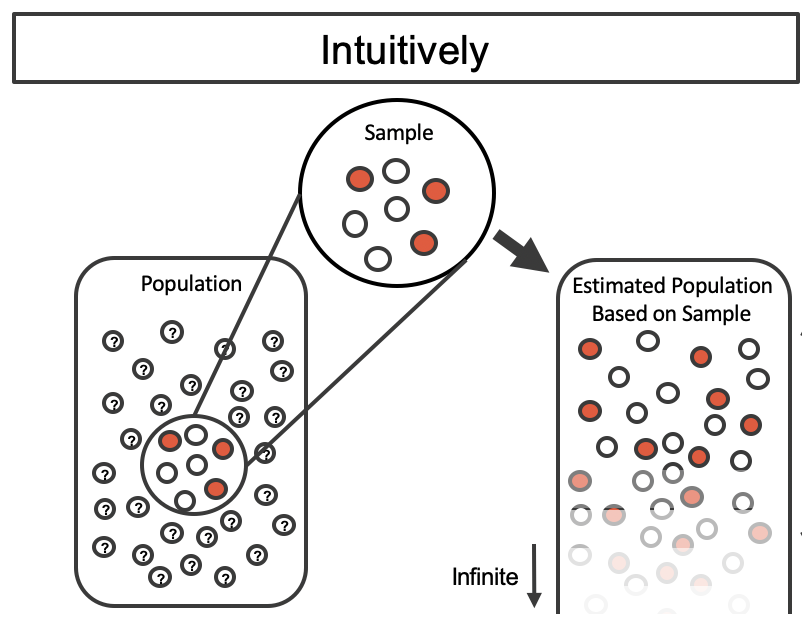
Source: Figure 12.1 of Introduction to Modern Statistics
Bootstrap Sampling
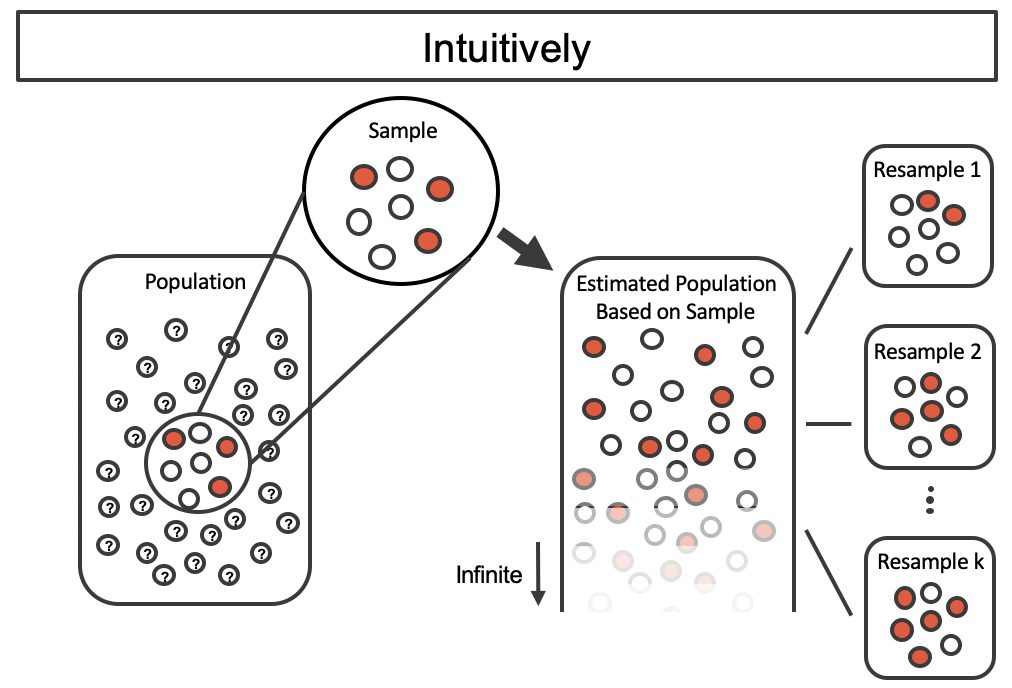
Source: Figure 12.2 of Introduction to Modern Statistics
Practical Bootstrap Sampling
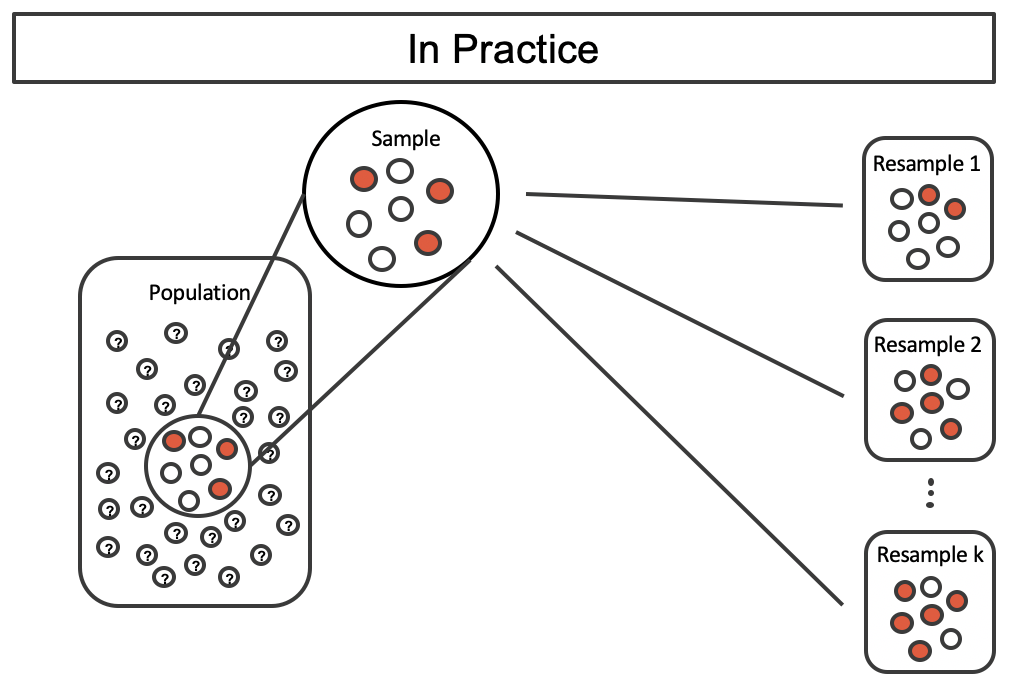
Source: Figure 12.4 of Introduction to Modern Statistics
R Lab infer 📦 in tidymodels
The objective of this package is to perform statistical inference using an expressive statistical grammar that coheres with the
tidyverseframework.


R Lab Visualize the Bootstrap Distribution
bt_dist <- ggplot(data = boot_sample, mapping = aes(x = stat)) +
geom_histogram(binwidth = 50) +
labs(title = "Bootstrap distribution of medians") + theme_bw()
bt_dist
R Lab Calculate the CI
Bootstrap Sample 1
Bootstrap Sample 2
Bootstrap Sample 3
Bootstrap Sample 4
Bootstrap Sample 5
so on and so forth…
Bootstrap Samples 1 - 5
Bootstrap Samples 1 - 100
Slopes of bootstrap samples
Bootstrapped CI
- A 95% confidence interval is bounded by the middle 95% of the bootstrap distribution.
R Lab Histogram of Bootstrap Samples
- BC\(_a\) is the accelerated bias-corrected percentile interval.
hist(car_boot)