Regression Diagnostics: Normality 📖
MATH 4780 / MSSC 5780 Regression Analysis
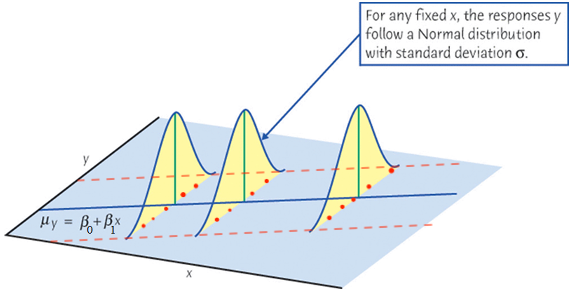
Detecting Nonnormality
The R-student residuals \(t_i \sim t_{n-p-1}\) if the model assumptions are correct.
Compare the distribution of the \(t_i\)s to \(t_{n-p-1}\) in QQ plot.
QQ plot of R-Student Residuals Comparing \(t_{n-p-1}\)
Density plot of R-Student Residuals
Correcting Skewness by Power Transformation
Box-Cox Transformation on \(y\)
A modified power transformation by Box and Cox (1964):
\[y^{(\lambda)} = \begin{cases} \frac{y^{\lambda}-1}{\lambda}, & \quad \lambda \ne 0\\ \ln y, & \quad \lambda = 0 \end{cases}\]
- For all \(\lambda\), \(y^{(\lambda)} = 1\) at \(y = 1\).
- The order of the transformed data \(y^{(\lambda)}\) is the same as that of \(y\), even for \(\lambda < 0.\)
R Lab R-Student Residuals
- See how
gdp,healthandginiaffectinfant. - R-Student residuals are right-skewed, suggesting transforming the response, infant mortality, down the ladder of powers.
R Lab Box-Cox Transformation
Code
mat <- matrix(r_stud)
for (lam in c(0.5, 0, -0.5, -1)) {
refit <- update(
ciafit, car::bcPower(infant, lam) ~ .
)
mat <- cbind(rstudent(refit), mat)
}
colnames(mat) <- c(-1, -0.5, "log", 0.5, 1)
boxplot(
mat, id = FALSE,
xlab = expression("Powers," ~ lambda),
ylab = expression(
"R-Student Residuals for "
~ Infant ^ (lambda))
)
Other Issues
- Apply power transformations to data with zero or negative values by adding a positive constant to the data to make all values positive.
- \(\log(y + 10)\) if all \(y > -10\).
- Power transformations are effective when the ratio of the largest to smallest values is sufficiently large.
- If \(y_{max}/y_{min} \approx 1\), power transformations are nearly linear.
- Increase the ratio by adding a negative constant, \((y_{max} - c)/(y_{min}-c)\)
- If acceptable, choose log transformation for simple interpretation.
(Intercept) gdp health gini
3.016 -0.044 -0.055 0.022 - All else held constant, for one unit increase of
gdp, the infant mortality rate is expected to be decreased, on average, by 4.3% because \(\exp(-0.044) = 0.957\).
![]()