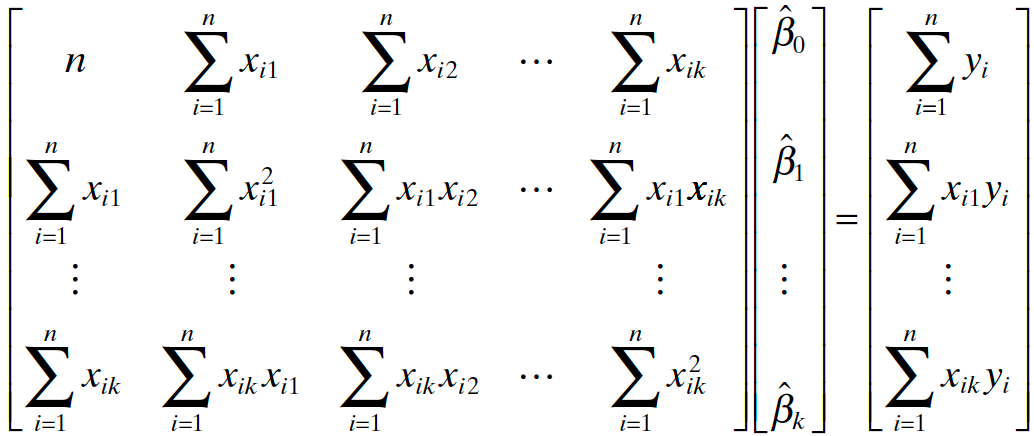The vector of residuals \(e_i = y_i - \hat{y}_i\) is \[\bf e = \bf y - \hat{\bf y} = \bf y - \bf X \bf b = \bf y -\bf H \bf y = (\bf I - \bf H) \bf y\]
Both \(\bf H\) and \(\bf I-H\) are symmetric and idempotent. They are projection matrices.
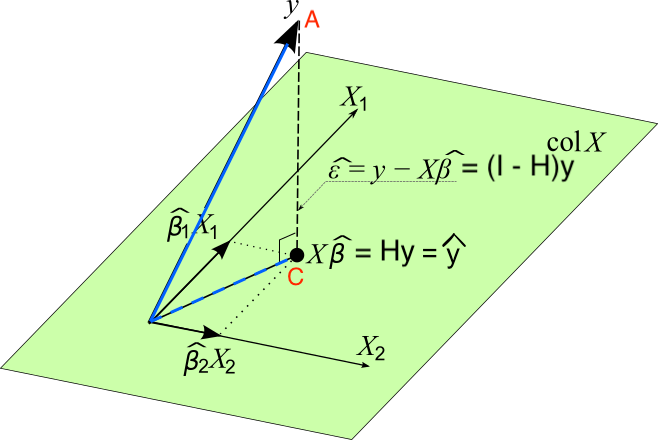
\(\bf H\) projects \(\bf y\) to \(\hat{\bf y}\) on the \(p\)-dimensional space spanned by columns of \(\bf X\), or the column space of \(\bf X\), \(Col(\bf X)\).
\(\bf I - H\) projects \(\bf y\) to \(\bf e\) on the space perpendicular to \(Col(\bf X)\), or \(Col(\bf X)^{\bot}\).
The distance is minimized when the point in the space is the foot of the line from \(A\)normal to the space. This is point \(C\). \(\small {\bf e} = ({\bf y - \hat{\bf y}}) = ({\bf y - X b}) = ({\bf I} - {\bf H}) {\bf y} \perp Col({\bf X})\)
\(\bf X'(y - Xb) = 0\)
Searching for the LS solution \(\bf b\) that minimizes \(SS_{res}\) is the same as locating the point \({\bf Xb} \in Col({\bf X})\) that is as close to \(\bf y\) as possible!
n <-length(y)I <-diag(n)res <- (I - H) %*% yres[1:4]
[1] -5.03 1.15 -0.05 4.92
delivery_lm$residuals[1:4]
1 2 3 4
-5.03 1.15 -0.05 4.92
## residual vector in the left null space of Xt(X) %*% res
[,1]
1 3.9e-13
cases -1.4e-12
distance -6.0e-11
Multivariate Normal Distribution
\({\bf y} \sim N(\boldsymbol \mu, {\bf \Sigma})\), and \({\bf Z = By + c}\) with a constant matrix \({\bf B}\) and vector \(\bf c\), then \[{\bf Z} \sim N({\bf B\boldsymbol \mu}, {\bf B \Sigma B}')\]
Otherwise, \(\beta_{2} = \beta_{4} = 0\). (Do not reject \(H_0\))
Given \(x_1\) and \(x_3\) in the model, we examine how much extra \(SS_R\) is increased ( \(SS_{res}\) is reduced) if \(x_2\) and \(x_4\) are added to the model.
Extra Sum-of-sqaures
Full Model: \(\bf y = X\boldsymbol \beta+\boldsymbol \epsilon\)
The \(SS_R\) due to \(\boldsymbol \beta_2\) given that \(\boldsymbol \beta_1\) is in the model is \[\begin{align} SS_R(\boldsymbol \beta_2|\boldsymbol \beta_1) &= SS_R(\boldsymbol \beta) - SS_R(\boldsymbol \beta_1)\\ &= SS_R(\boldsymbol \beta_1, \boldsymbol \beta_2) - SS_R(\boldsymbol \beta_1) \end{align}\] with \(r\) dfs.
This is the extra sum of squares due to \(\boldsymbol \beta_2\).
It measures the increase in the \(SS_R\) that results from adding regressors in \({\bf X}_2\) to the model that already contains regressors in \({\bf X}_1\).
Under \(H_0\) that \(\boldsymbol \beta_2 = \bf 0\), \(F_{test} \sim F_{r, n-p}\). \((p = k+1)\).
Reject \(H_0\) if \(F_{test} > F_{\alpha, r, n-p}\).
Given the regressors of \({\bf X}_1\) are in the model,
If the regressors of \({\bf X}_2\) contribute much, \(SS_R(\boldsymbol \beta_2|\boldsymbol \beta_1)\) will be large.
A large \(SS_R(\boldsymbol \beta_2|\boldsymbol \beta_1)\) implies a large \(F_{test}\).
A large \(F_{test}\) tends to reject \(H_0\), and conclude that \(\boldsymbol \beta_2 \ne \bf 0\).
\(\boldsymbol \beta_2 \ne \bf 0\) means the regressors of \({\bf X}_2\) provide additional explanatory and prediction power that \({\bf X}_1\) cannot provide.
Example: Delivery Data
\(H_0: \beta_2 = 0 \qquad H_1: \beta_2 \ne 0\)
Full model: \(y = \beta_0 + \beta_1x_1+\beta_2x_2+\epsilon\)
\(\hat{y} = 5 + x_1 + 1000x_2\). Can we say the effect of \(x_2\) on \(y\) is 1000 times larger than the effect of \(x_1\)?
Nope! If \(x_1\) is measured in litres and \(x_2\) in millilitres, although \(b_2\) is 1000 times larger than \(b_1\), both effects on \(\hat{y}\) are identical.
The units of \(\beta_j\) are \(\frac{\text{units of } y}{\text{units of } x_j}\)
\(\beta_2\): delivery time (min) \((y)\) per distance (ft) walked by the driver \((x_2)\).
It is helpful to work with dimensionless or standardized coefficients.
comparison
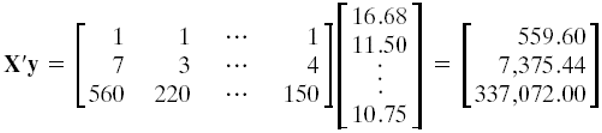
get rid of round-off errors in \({\bf (X'X)}^{-1}\).
In Intro Stats, how do we standardize a variable?
Unit Normal Scaling
\(z_{ij} = \frac{x_{ij}-\overline{x}_j}{s_j}, \, i = 1, \dots, n, \, j = 1, \dots, k\), where \(s_j\) is the sample SD of \(x_j\).
\(y^*_{i} = \frac{y_{i}-\overline{y}}{s_y}, \, i = 1, \dots, n\), where \(s_y\) is the sample SD of \(y\).
The scaled predictors and response have mean 0 and variance 1.
The new model: \[y_i^* = \alpha_1z_{i1} + \alpha_2z_{i2} + \cdots + \alpha_kz_{ik} + \epsilon_i\]
Why no intercept term \(\alpha_0\)?
The least-squares estimator for \(\boldsymbol \alpha\): \[{\bf a} = {\bf (Z'Z)}^{-1} {\bf Z'y}^*\]
R Lab Standardized Coefficients
## unit normal scalingscale_data <-scale(delivery_data, center =TRUE, scale =TRUE) ## becomes a matrixapply(scale_data, 2, mean)