
Multiple Linear Regression 👨💻
MATH 4780 / MSSC 5780 Regression Analysis
Why Multiple Regression?
- Our target response may be affected by several factors.
- Total sales \((Y)\) and amount of money spent on advertising on YouTube (YT) \((X_1)\), Facebook (FB) \((X_2)\), Instagram (IG) \((X_3)\).


- Predict sales based on the three advertising expenditures and see which medium is more effective.
Fit Separate Simple Linear Regression Models
Fit three separate independent SLR models:
❌ Fitting a separate SLR model for each predictor is not satisfactory.
I hope you don’t feel…

What I hope is…

Sample MLR Model
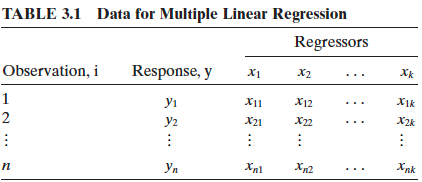
- Given the training sample data \((x_{11}, \dots, x_{1k}, y_1), (x_{21}, \dots, x_{2k}, y_2), \dots, (x_{n1}, \dots, x_{nk}, y_n),\)
- The sample MLR model: \[\begin{align} y_i &= \beta_0 + \beta_1x_{i1} + \beta_2x_{i2} + \dots + \beta_k x_{ik} + \epsilon_i \\ &= \beta_0 + \sum_{j=1}^k\beta_j x_{ij} + \epsilon_i, \quad i = 1, 2, \dots, n \end{align}\]
Regression Hyperplane
- SLR: regression line
- MLR: regression hyperplane or response surface
- \(y = \beta_0 + \beta_1x_1 + \beta_{2}x_2 + \epsilon\)
- \(E(y \mid x_1, x_2) = 50 + 10x_1 + 7x_2\)
Response Surface : Interaction Model
- \(y = \beta_0 + \beta_1x_1 + \beta_{2}x_2 + \beta_{12}x_1x_2 + \epsilon\)
- This is in fact a linear regression model: let \(\beta_3 = \beta_{12}, x_3 = x_1x_2\).
- \(E(y \mid x_1, x_2) = 50 + 10x_1 + 7x_2 + 5x_1x_2\)
- 😎 🤓 A linear model generates a nonlinear response surface!
Response Surface : 2nd Order with Interaction Model
- \(y = \beta_0 + \beta_1x_1 + \beta_{2}x_2 + \beta_{11}x_1^2 + \beta_{22}x_2^2 + \beta_{12}x_1x_2 + \epsilon\)
- \(E(y) = 800+10x_1+7x_2 -8.5x_1^2-5x_2^2- 4x_1x_2\)
- 😎 🤓 A linear regression model can describe a complex nonlinear relationship between the response and predictors!
Geometry of Least Square Estimation
R Lab Scatterplot Matrix
pairs(delivery_data)
R Lab 3D Scatterplot
Code
par(mgp = c(2, 0.8, 0), las = 1, mar = c(4, 4, 0, 0))
library(scatterplot3d)
scatterplot3d(x = delivery_data$cases, y = delivery_data$distance, z = delivery_data$time,
xlab ="cases", ylab = "distance", zlab = "time",
xlim = c(2, 30), ylim = c(36, 1640), zlim = c(8, 80),
box = TRUE, color = "blue", mar = c(3, 3, 0, 2), angle = 30, pch = 16)
R Lab Regression Plane
Confidence Region
- The \((1-\alpha)100\%\) CI for a set of \(b_j\)s will be an elliptically-shaped region!
Code
par(mgp = c(2.8, 0.9, 0), mar = c(4, 4, 2, 0))
## confidence region
car::confidenceEllipse(
delivery_lm,
levels = 0.95,
which.coef = c("cases", "distance"),
main = expression(
paste("95% Confidence Region for ",
beta[1], " and ", beta[2])
)
)
## marginal CI for cases
abline(v = ci[2, ], lty = 2, lwd = 2)
## marginal CI for distance
abline(h = ci[3, ], lty = 2, lwd = 2)
points(x = 1.4, y = 0.01, col = "red", cex = 2, pch = 16)
points(x = 2, y = 0.008, col = "black", cex = 2, pch = 16)
- Some points (red) within the marginal intervals are implausible according to the joint region.
- The joint region includes values of the coefficient for cases (black), for example, that are excluded from the marginal interval.
R Lab Predictor Effect Plots
library(effects)
plot(effects::predictorEffects(mod = delivery_lm))
R Lab ANOVA Table: Null vs. Full
Testing coefficients is like model comparison: Compare the full model with the model under \(H_0\)!
-
Full model: including both
casesanddistancepredictors - Null model: no predictors \((\beta_1 = \beta_2 = 0)\)

Inference Pitfalls
- The test \(H_0:\beta_j = 0\) will always be rejected as long as the sample size is large enough, even \(x_j\) has a very small effect on \(y\).
- Consider the practical significance of the result, not just the statistical significance.
- Use the confidence interval to draw conclusions instead of relying only p-values.
- If the sample size is small, there may not be enough evidence to reject \(H_0:\beta_j = 0\).
- DON’T immediately conclude that the variable has no association with the response.
- There may be a linear association that is just not strong enough to detect given your data, or there may be a non-linear association.
![]()