Dr. Cheng-Han Yu Department of Mathematical and Statistical Sciences Marquette University
Model
Simple Linear Regression Model (Population)
Simple: Only one predictor \(X\).
Linear: the regression function is linear, i.e., \(f(X) = \beta_0 + \beta_1 X\).
For the \(i\)-th measurement in the target population, \[Y_i = \beta_0 + \beta_1X_i + \epsilon_i\]
\(Y_i\): the \(i\)-th value of the response (random) variable.
\(X_i\): the \(i\)-th known fixed value of the predictor.
\(\epsilon_i\): the \(i\)-th random error with assumption \(\epsilon_i \stackrel{iid}{\sim} N(0, \sigma^2)\).
\(\beta_0\), \(\beta_1\) and \(\sigma^2\) are fixed unknown parameters to be estimated from the training sample after we collect them.
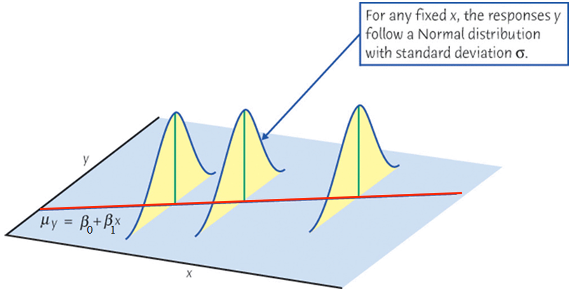
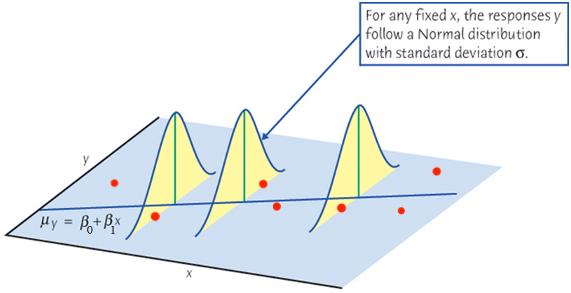
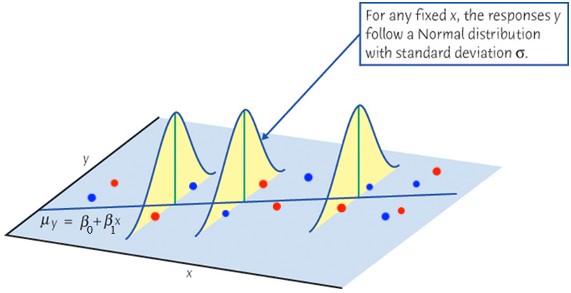
When we collect data \(\{ (x_1, y_1), (x_2, y_2), \dots, (x_n, y_n)\},\)\(y\) is assumed drawn from a normal distribution. Its value varies around its mean \(\mu_y\).
When we collect data \(\{ (x_1, y_1), (x_2, y_2), \dots, (x_n, y_n)\},\)\(y\) is assumed drawn from a normal distribution. Its value varies around its mean \(\mu_y\).
Conditional Mean of \(Y_i\) given a value of \(X_i\)
The mean response of \(Y\), \(\mu_{Y\mid X} = E(Y\mid X)\), has a straight-line relationship with \(X\) given by the population regression line \[\mu_{Y\mid X} = \beta_0 + \beta_1X\]
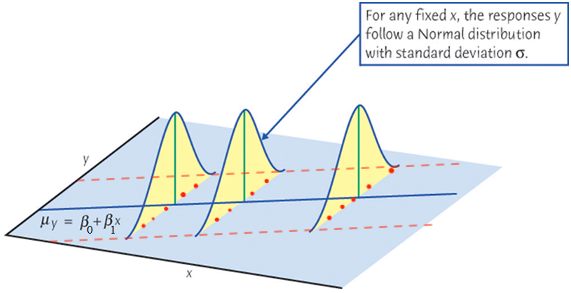
Conditional Variance of \(Y_i\) given a value of \(X_i\)
For a random variable \(Z\) and a constant \(c \in \mathbf{R}\), \(\mathrm{Var}(c+Z) = \mathrm{Var}(Z)\).
\[\begin{align*}
\mathrm{Var}(Y_i \mid X_i) &= \mathrm{Var}(\beta_0 + \beta_1X_i + \epsilon_i) \\
&= \mathrm{Var}(\epsilon_i) = \sigma^2
\end{align*}\] The variance of \(Y\) does not depend on \(X\).
For a random variable \(Z \sim N(\mu, \sigma^2)\) and a constant \(c \in \mathbf{R}\), \(c+Z \sim N(c + \mu, \sigma^2)\).
\[\begin{align*}
Y_i \mid X_i \stackrel{indep}{\sim} N(\beta_0 + \beta_1X_i, \sigma^2)
\end{align*}\] For any fixed value of \(X_i = x\), the response \(Y_i\) varies according to \(N(\mu_{Y_i\mid X_i = x}, \sigma^2)\).
Job: Collect data and estimate the unknown \(\beta_0\), \(\beta_1\) and \(\sigma^2\)!
Parameter Estimation and Model Fitting
Idea of Fitting
Interested in \(\beta_0\) and \(\beta_1\) in the sample regression model:
Use sample statistics \(b_0\) and \(b_1\) computed from our sample data to estimate \(\beta_0\) and \(\beta_1\).
\(\hat{y}_{i} = b_0 + b_1~x_{i}\) is called fitted value of \(y_i\), a point estimate of the mean \(\mu_{y|x_i}\) and \(y_i\) itself.
Fitting a Regression Line \(\hat{Y} = b_0 + b_1X\)
Given the training sample \(\{ (x_1, y_1), (x_2, y_2), \dots, (x_n, y_n)\},\)
Which sample regression line is the best?
What are the best estimators \(b_0\) and \(b_1\) for \(\beta_0\) and \(\beta_1\)?
What does “best” mean? Ordinary Least Squares (OLS)
Choose the best\(b_0\) and \(b_1\) or the sample regression line minimizing the sum of squared residuals\[SS_{res} = e_1^2 + e_2^2 + \dots + e_n^2 = \sum_{i = 1}^n e_i^2.\]
The residual\(e_i = y_i - \hat{y}_i = y_i - (b_0 + b_1x_i)\) is a point estimate of \(\epsilon_i\).
If \(b_0\) and \(b_1\) are the best estimators, plug \(e_i = y_i - (b_0 + b_1x_i)\) into \(SS_{res}\), we have
\[\begin{align} SS_{res} &= (y_1 - b_0 - b_1x_1)^2 + (y_2 - b_0 - b_1x_2)^2 + \dots + (y_n - b_0 - b_1x_n)^2\\ &= \sum_{i=1}^n(y_i - b_0 - b_1x_i)^2 \end{align}\] that is the smallest comparing to any other \(SS_{res} = \sum_{i=1}^n(y_i - a_0 - a_1x_i)^2\) that uses another pair of estimators \((a_0, a_1) \ne (b_0, b_1)\).
Visualizing Residuals
Visualizing Residuals (cont.)
Visualizing Residuals (cont.)
Least Squares Estimates (LSE)
The least squares approach choose \(b_0\) and \(b_1\) that minimize the \(SS_{res}\), i.e., \[(b_0, b_1) = \arg\min_{\alpha_0, \alpha_1} \sum_{i=1}^n(y_i - \alpha_0 - \alpha_1x_i)^2\]
Take derivative w.r.t. \(\alpha_0\) and \(\alpha_1\), setting both equal to zero: \[\left.\frac{\partial SS_{res}}{\partial\alpha_0}\right\vert_{b_0, b_1} = \left.\sum_{i=1}^n\frac{\partial (y_i - \alpha_0 - \alpha_1x_i)^2}{\partial\alpha_0}\right\vert_{b_0, b_1} = -2 \sum_{i=1}^n(y_i - b_0 - b_1x_i) = 0\]\[\left. \frac{\partial SS_{res}}{\partial\alpha_1}\right\vert_{b_0, b_1} = \left.\sum_{i=1}^n\frac{\partial (y_i - \alpha_0 - \alpha_1x_i)^2}{\partial\alpha_1}\right\vert_{b_0, b_1} = -2 \sum_{i=1}^nx_i(y_i - b_0 - b_1x_i) = 0\] The two equations are called the normal equations.
Least Squares Estimates: Solve for \(\alpha_0\) and \(\alpha_1\)
# A tibble: 234 × 11
manufacturer model displ year cyl trans drv cty hwy fl class
<chr> <chr> <dbl> <int> <int> <chr> <chr> <int> <int> <chr> <chr>
1 audi a4 1.8 1999 4 auto(l5) f 18 29 p compa…
2 audi a4 1.8 1999 4 manual(m5) f 21 29 p compa…
3 audi a4 2 2008 4 manual(m6) f 20 31 p compa…
4 audi a4 2 2008 4 auto(av) f 21 30 p compa…
5 audi a4 2.8 1999 6 auto(l5) f 16 26 p compa…
6 audi a4 2.8 1999 6 manual(m5) f 18 26 p compa…
# ℹ 228 more rows
R Lab Scatter Plot
plot(x =mpg$displ, y =mpg$hwy, las =1, pch =19, col ="navy", cex =0.5, xlab ="Displacement (litres)", ylab ="Highway MPG", main ="Highway MPG vs. Engine Displacement (litres)")
plot(x =mpg$displ, y =mpg$hwy, las =1, pch =19, col ="navy", cex =0.5, xlab ="Displacement (litres)", ylab ="Highway MPG", main ="Highway MPG vs. Engine Displacement (litres)")abline(reg_fit, col ="#FFCC00", lwd =3)#<<
Properties of Least Squares Fit
Both \(b_0\) and \(b_1\) are linear combinations of \(y_1, \dots, y_n\).
👉 The LS regression line passes through the centroid of data \((\overline{x}, \overline{y})\).
👉 Inner product of residual and predictor is zero.\[\scriptstyle \sum_{i=1}^nx_ie_i = 0\]
👉 Inner product of residual and fitted value is zero.\[\scriptstyle \sum_{i=1}^n\hat{y}_ie_i = 0\]
Estimation for \(\sigma^2\)
Think of \(\sigma^2\) as variance around the line or the mean squared error.
The estimate of \(\sigma^2\), denoted as \(s^2\) computed from the sample data is \[s^2 = \frac{SS_{res}}{n-2} = \frac{\sum_{i=1}^n(y_i - \hat{y}_i)^2}{n-2} = MS_{res}\]
The estimated variance \(MS_{res}\), called mean squared residual, is often shown in computer output as \(\texttt{MS(Error)}\) or \(\texttt{MS(Residual)}\).
\(E(MS_{res}) = \sigma^2\), i.e., \(s^2\) is an unbiased estimator for \(\sigma^2\). 👍
Model-dependent estimate of \(\sigma^2\)
\(s\): the residual standard error or standard error of regression, is a measure of the lack of fit of the regression model to the data.
If \(\hat{y}_i \approx y_i\), then \(s\) will be small, and the model fits the data well.
If \(\hat{y}_i\) is far away from \(y_i\), \(s\) may be large, indicating the model does not fit the data well.
# residual standard error (sigma_hat)summ_reg_fit$sigma
[1] 3.84
# from reg_fitsqrt(sum(reg_fit$residuals^2)/reg_fit$df.residual)
[1] 3.84
Inference
Interval Estimation and Hypothesis Testing
The inference methods requires the model assumptions to be satisfied!
Sampling Distribution of \(b_0\) and \(b_1\)
If \(y_i\) ( given \(x_i\) ) is normally distributed, do \(b_0\) and \(b_1\) follow normal distribution too?
If \(Z_1, \dots, Z_n\) are normal variables and constants \(c_1, \dots, c_n \in \mathbf{R}\), then \(c_1Z_1 + \dots + c_nZ_n\) is also a normal variable.
...
lm(formula = hwy ~ displ, data = mpg)
Residuals:
Min 1Q Median 3Q Max
-7.104 -2.165 -0.224 2.059 15.010
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 35.698 0.720 49.5 <2e-16 ***
displ -3.531 0.195 -18.1 <2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
...
summ_reg_fit$coefficients
Estimate Std. Error t value Pr(>|t|)
(Intercept) 35.70 0.720 49.6 2.12e-125
displ -3.53 0.195 -18.2 2.04e-46
Testing \(H_0: \beta_0 = 0\) and \(H_0: \beta_1 = 0\)
Interpretation of Testing Results
\(H_0: \beta_1 = 0 \quad H_1: \beta_1 \ne 0\)
Failing to reject \(H_0: \beta_1 = 0\) implies there is no linear relationship between \(Y\) and \(X\).
If we reject \(H_0: \beta_1 = 0\), does it mean \(X\) and \(Y\) are linearly related?
Test of Significance of Regression
Rejecting \(H_0: \beta_1 = 0\) could mean
the straight-line model is adequate
better results could be obtained with a more complicated model
Analysis of Variance (ANOVA) Approach
\(X\) - \(Y\) Relationship Explains Some Deviation
Suppose we only have data \(Y\) and have no information about \(X\) or no information about the relationship between \(X\) and \(Y\). How do we predict a value of \(Y\)?
Our best guess would be \(\overline{y}\) if the data have no pattern, i.e., \(\hat{y}_i = \overline{y}\).
As we were treating \(X\) and \(Y\) as uncorrelated.
The (total) deviation from the mean is \((y_i - \overline{y})\).
If \(X\) and \(Y\) are linearly related, fitting a linear regression helps us predict the value of \(Y\) when the value of \(X\) is provided.
\(\hat{y}_i = b_0 + b_1x_i\) is closer to \(y_i\) than \(\overline{y}\).
The regression model explains some deviation of \(y\).
Partition of Deviation
Total deviation = Deviation explained by regression + Unexplained deviation
Total SS \((SS_T)\) = Regression SS \((SS_R)\) + Residual SS \((SS_{res})\)
\(df_T = df_R + df_{res}\)
\(\color{blue}{(n-1) = 1 +(n-2)}\)
\(df_T = n - 1\): lose 1 df with constraint \(\sum_{i=1}^n(y_i - \overline{y}) = 0\)
\(df_R = 1\): all \(\hat{y}_i\) are on the regression line with 2 dfs (intercept and slope), but with constraint \(\sum_{i=1}^n(\hat{y}_i - \overline{y}) = 0\)
\(df_{res} = n - 2\): lose 2 dfs because \(\beta_0\) and \(\beta_1\) are estimated by \(b_0\) and \(b_1\), which are linear combo of \(y_i\)
ANOVA for Testing Significance of Regression
A larger value of \(F_{test}\) indicates that regression is significant.
Analysis of Variance Table
Response: hwy
Df Sum Sq Mean Sq F value Pr(>F)
displ 1 4848 4848 329 <2e-16 ***
Residuals 232 3414 15
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
For \(H_0: \beta_1 = 0\) in SLR, \(t_{test}^2 = F_{test}\).
summ_reg_fit$coefficients
Estimate Std. Error t value Pr(>|t|)
(Intercept) 35.70 0.720 49.6 2.12e-125
displ -3.53 0.195 -18.2 2.04e-46
summ_reg_fit$coefficients[2, 3]^2
[1] 329
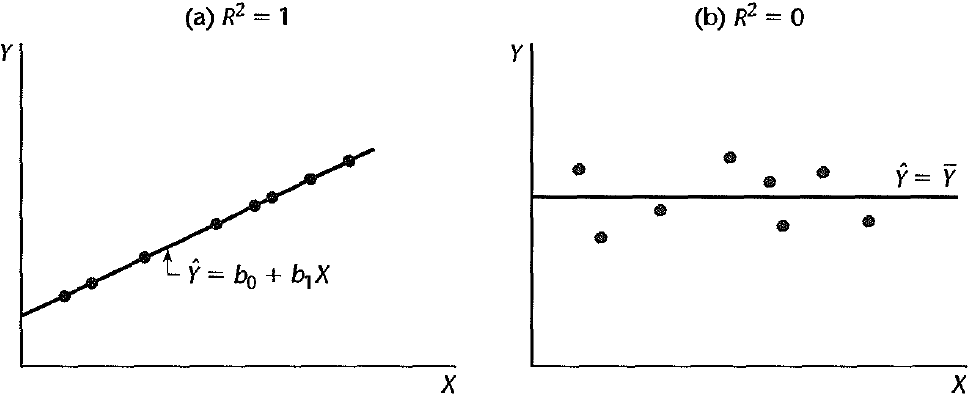
Coefficient of Determination
The coefficient of determination\((R^2)\) is the proportion of the variation in \(y\) that is explained by the regression model: \[R^2 = \frac{SS_R}{SS_T} =\frac{SS_T - SS_{res}}{SS_T} = 1 - \frac{SS_{res}}{SS_T}\]
\(R^2\) as the proportionate reduction of total variation associated with the use of \(X\).
...
Estimate Std. Error t value Pr(>|t|)
(Intercept) 35.698 0.720 49.5 <2e-16 ***
displ -3.531 0.195 -18.1 <2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 3.84 on 232 degrees of freedom
Multiple R-squared: 0.587, Adjusted R-squared: 0.585
F-statistic: 329 on 1 and 232 DF, p-value: <2e-16
...
summ_reg_fit$r.squared
[1] 0.587
Prediction
Predicting the Mean Response: Sampling Distribution
With predictor value \(x = x_0\), we want to estimate the mean response \[E(y\mid x_0) = \mu_{y|x_0} = \beta_0 + \beta_1 x_0\].
The mean highway MPG \(E(y \mid x_0)\) when displacement is \(x = x_0 = 5.5\).
If \(x_0\) is within the range of \(x\), an unbiased point estimate of \(E(y\mid x_0)\) is \[\widehat{E(y\mid x_0)} = \hat{\mu}_{y | x_0} = b_0 + b_1 x_0\]
The sampling distribution of \(\hat{\mu}_{y | x_0}\) is \[N\left( \mu_{y | x_0} = \beta_0 + \beta_1 x_0, \sigma^2\left(\frac{1}{n} + \frac{(x_0 - \overline{x})^2}{S_{xx}} \right) \right)\]
The \((1-\alpha)100\%\) CI for \(E(y\mid x_0)\) is \(\boxed{\hat{\mu}_{y | x_0} \pm t_{\alpha/2, n-2} s\sqrt{\frac{1}{n} + \frac{(x_0 - \overline{x})^2}{S_{xx}}}}\).
Does the length of the CI for \(E(y\mid x_0)\) stay the same at any location of \(x_0\)?
Predicting New Observations: Sampling Distribution
Predict the value of a new observation \(y_0\) with \(x = x_0\).
The highway MPG of a car\(y_0(x_0)\) when its displacement is \(x = x_0 = 5.5\).
An unbiased point estimate of \(y_0(x_0)\) is \[\hat{y}_0(x_0) = b_0 + b_1 x_0\]
What is the sampling distribution of \(\hat{y}_0\)?
Influential point: A point that strongly affects the slope of the line. (unusual in \(x\) direction)
Considerations in Regression: Causal Relationship?
Considerations in Regression: Unknown Predictor
Maximum daily load \((Y)\) on an electric power generation system and the maximum daily temperature \((X)\).
To predict tomorrow maximum daily load, we must first know tomorrow maximum temperature.
The prediction of maximum load is conditional on the temperature forecast.
Maximum Likelihood Estimation (MLE)*
Likelihood Function
Maximum likelihood estimation is a method of finding point estimators.
Suppose \(y_i \stackrel{iid}{\sim} f(y|\theta)\)
The joint probability function of the data \((y_1, y_2, \dots, y_n)\) is \[f(y_1, y_2, \dots, y_n|\theta) = \prod_{i = 1}^nf(y_i|\theta)\]
When the function is viewed as a function of \(\theta\), with the data given, it is called the likelihood function\(L(\theta|{\bf y} = (y_1, y_2, \dots, y_n))\): \[L(\theta|{\bf y}) = \prod_{i = 1}^nf(y_i|\theta)\]
\(L(\theta|{\bf y})\) is not a probability or density function.
Likelihood Function
For easier calculation and computation, we work with the log-likelihood function\[\ell(\theta|{\bf y}) := \log L(\theta|{\bf y})\]
Example: Maximum Likelihood Estimation
Maximizing \(L(\theta)\) with respect to \(\theta\) yields the maximum likelihood estimator of \(\theta\), i.e., \[\hat{\theta}_{ML} = \underset{\theta}{\arg \max} L(\theta) = \underset{\theta}{\arg \max} \log L(\theta)\]
Intuition: Given the data \((y_1, y_2, \dots, y_n)\), we are finding a value of parameter \(\theta\) so that the given data set is most likely to be sampled.
Example: Suppose \(Y_1, Y_2, \dots, Y_n \stackrel{iid}{\sim} Bernoulli(\theta)\), where \(\theta\), the probability of success, is the unknown parameter to be estimated.
What is the Bernoulli distribution?
The probability function of \(Y_i\) is \(P(Y_i = y_i) = f(y_i) = \theta^{y_i}(1-\theta)^{1-y_i}\) for \(y_i=0, 1\). \[L(\theta) = \prod_{i = 1}^nf(y_i|\theta) = \prod_{i = 1}^n\theta^{y_i}(1-\theta)^{1-y_i} = \theta^{\sum_{i=1}^ny_i}(1-\theta)^{n-\sum_{i=1}^ny_i}\]