If \(X \sim N(\mu_X, \sigma_X^2)\) and \(Y \sim N(\mu_Y, \sigma_Y^2)\) and \(X\) and \(Y\) are independent. Then for \(a, b \in \mathbf{R}\), \[aX + bY \sim N\left(a\mu_X+b\mu_Y, \color{red}{a^2} \color{black} \sigma_X^2 + \color{red}{b^2} \color{black} \sigma_Y^2\right)\]
What is the distribution of \(a_1Y_1 + a_2Y_2 + \cdots + a_nY_n\) if \(Y_i \sim N(\mu_i, \sigma^2_i)\) and \(Y_i\)s are independent?
Statistics Comes In
Suppose each data point \(Y_i\) of the sample \((Y_1, Y_2, \dots, Y_n)\) is a random variable from the same population whose distribution is \(N(\mu, \sigma^2)\), and \(Y_i\)s are independent each other: \[Y_i \stackrel{iid}{\sim} N(\mu, \sigma^2), \quad i = 1, 2, \dots, n\]
Statistics Comes In: Sampling Distribution
If \(Y_i \stackrel{iid}{\sim} N(\mu, \sigma^2), \quad i = 1, 2, \dots, n\),
Inference: \(\mu\) and \(\sigma^2\) are unknown, and \(\overline{y}\) and \(s^2\) are point estimates for \(\mu\) and \(\sigma^2\), respectively.
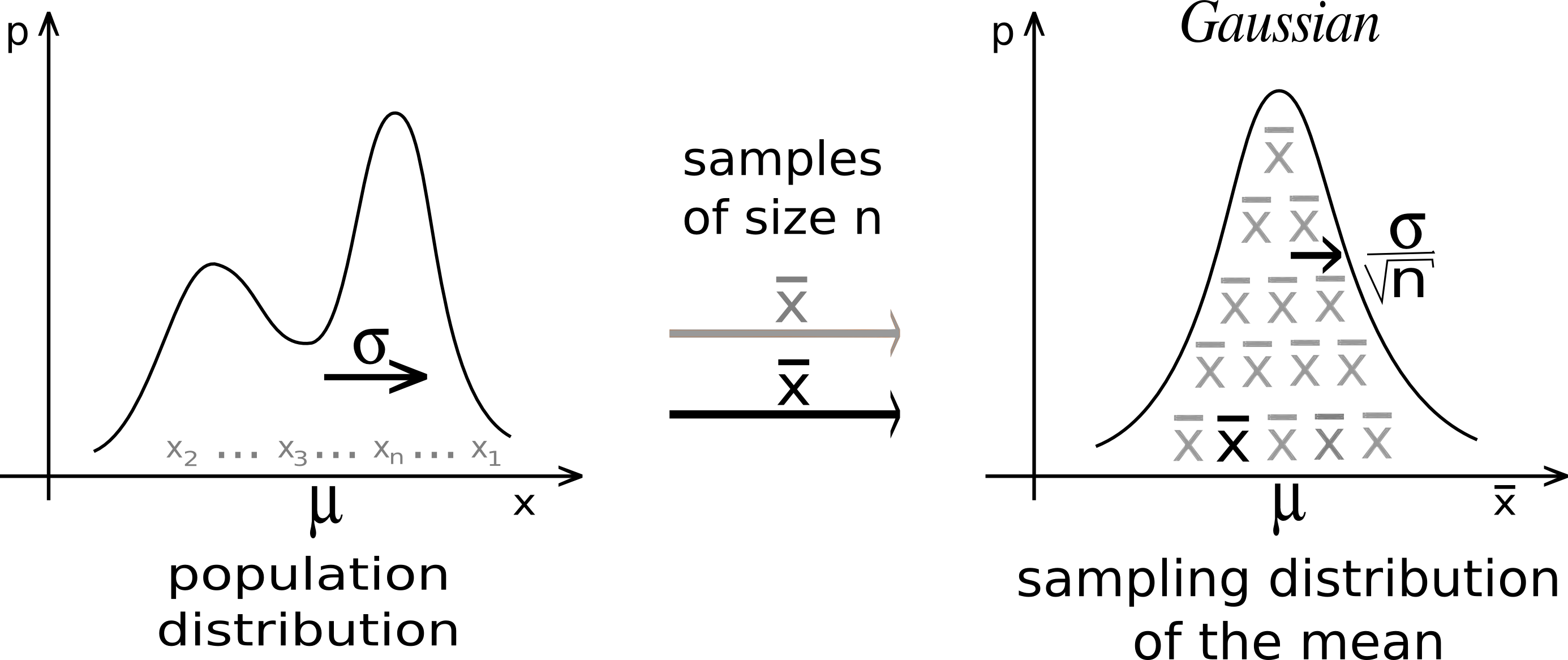
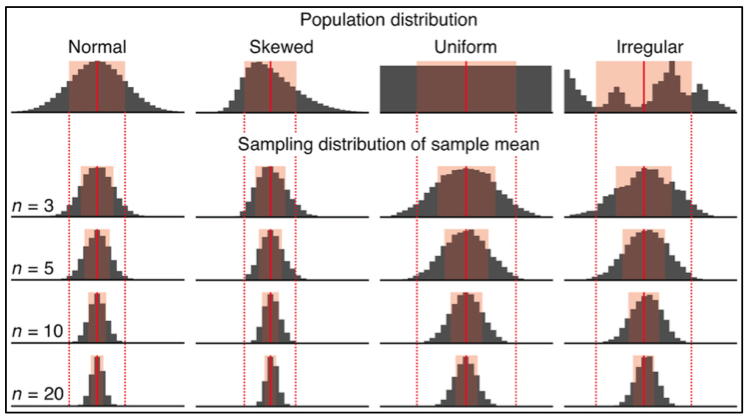
Why Use Normal? Central Limit Theorem (CLT)
\(X_1, X_2, \dots, X_n\) are i.i.d. variables with mean \(\mu\) and variance \(\sigma^2 < \infty\).
As \(n\) increases, the sampling distribution of \(\overline{X}_n = \frac{\sum_{i=1}^nX_i}{n}\) looks more and more like \(N(\mu, \frac{\sigma^2}{n})\), regardless of the distribution from which we are sampling \(X_i\)!
Nature Methods 10, 809–810 (2013)
\((1-\alpha)100\%\) Confidence Interval for \(\mu\)
With sample data of size \(n\), \(\left( \overline{y}- t_{\alpha/2, n-1}\frac{s}{\sqrt{n}}, \overline{y} + t_{\alpha/2, n-1}\frac{s}{\sqrt{n}} \right)\) is our \((1-\alpha)100\%\) CI for \(\mu\).
Hypothesis Testing
\(H_0: \mu = \mu_0 \text{ vs. } H_1: \mu > \mu_0\), or \(\mu < \mu_0\), or \(\mu \ne \mu_0\)
The significant level \(\alpha = P(\text{Reject } H_0 \mid H_0 \text{ is true}) = P(\text{Type I error})\)
The test statistic is \(t_{test} = \frac{\overline{y} - \color{blue}{\mu_0}}{s/\sqrt{n}}\), a value from \(T \sim t_{n-1}\).
When calculating a test statistic, we assume \(H_0\) is true.